Com Construir un Assistent d’IA per a WhatsApp
De la Idea a Producció
El problema real que vam resoldre
Un institut ortopèdic ens va contactar amb un problema concret: les infermeres prequirúrgiques dedicaven hores a les mateixes preguntes per telèfon. «Puc beure aigua abans de la cirurgia?», «On m’he de presentar?», «Puc seguir prenent la meva medicació habitual?». Consultes repetides, centenars de vegades al mes, en les 48 hores prèvies a cada intervenció programada.
La solució òbvia era automatitzar, però no amb un xatbot de regles rígides que ningú fa servir, sinó amb un assistent conversacional intel·ligent que entén context, respon en llenguatge natural i, sobretot, sap quan no ha de respondre.
Aquest article documenta com ho vam construir, què vam aprendre i per què aquesta arquitectura serveix a qualsevol empresa que vulgui automatitzar WhatsApp sense perdre qualitat ni control.
Per què WhatsApp (i per què ara)
WhatsApp supera els 2.000 milions d’usuaris actius. A Espanya i Llatinoamèrica no és «una opció de missatgeria»: és el canal per defecte. Els pacients confirmen cites; els clients pregunten per comandes; el personal coordina torns.
Durant anys, integrar automatització en aquest canal volia dir contractes enterprise, plataformes complexes o solucions fràgils. Això va canviar quan Twilio va democratitzar l’accés a l’API de WhatsApp Business amb webhooks simples.
Combinat amb models de llenguatge actuals (Claude, GPT-4), la barrera per desplegar un assistent conversacional útil és prou baixa com perquè un equip petit arribi a producció en dies, no en mesos.
El cas d’estudi: un assistent prequirúrgic
Vam desenvolupar un pilot per al sector sanitari: un assistent que cobreix les consultes més freqüents abans de la cirurgia, sense costos de plataforma enterprise ni la rigidesa dels xatbots tradicionals.
No ho és
Un xatbot de regles amb camins predefinits.
Un assistent general sense límits d’abast.
Una IA que inventa respostes.
Una plataforma propietària cara.
Sí que ho és
Un agent conversacional amb context acotat.
Una solució tècnicament simple i econòmicament viable.
Un sistema amb historial de conversa per usuari.
Una arquitectura que fonamenta les respostes en coneixement de domini.
El principi fonamental: grounding
La restricció clau és el grounding: el model només respon el que pot sustentar amb el context proporcionat. Si la pregunta és fora d’abast, l’assistent reconeix el límit i deriva al canal humà adequat.
Això no és una limitació, és la característica principal. En entorns clínics, un agent que inventa és pitjor que no tenir agent. En la majoria d’indústries, «no ho sé, contacta amb X» millora una resposta incorrecta.
Exemple de conversa
En el pilot, l’assistent va respondre sobre el protocol de dejuni i la logística de check-in amb precisió, citant la base de coneixement i tancant amb clàusules de seguretat (per exemple, recordar que si el cirurgià va donar altres instruccions, prevalen les del cirurgià).
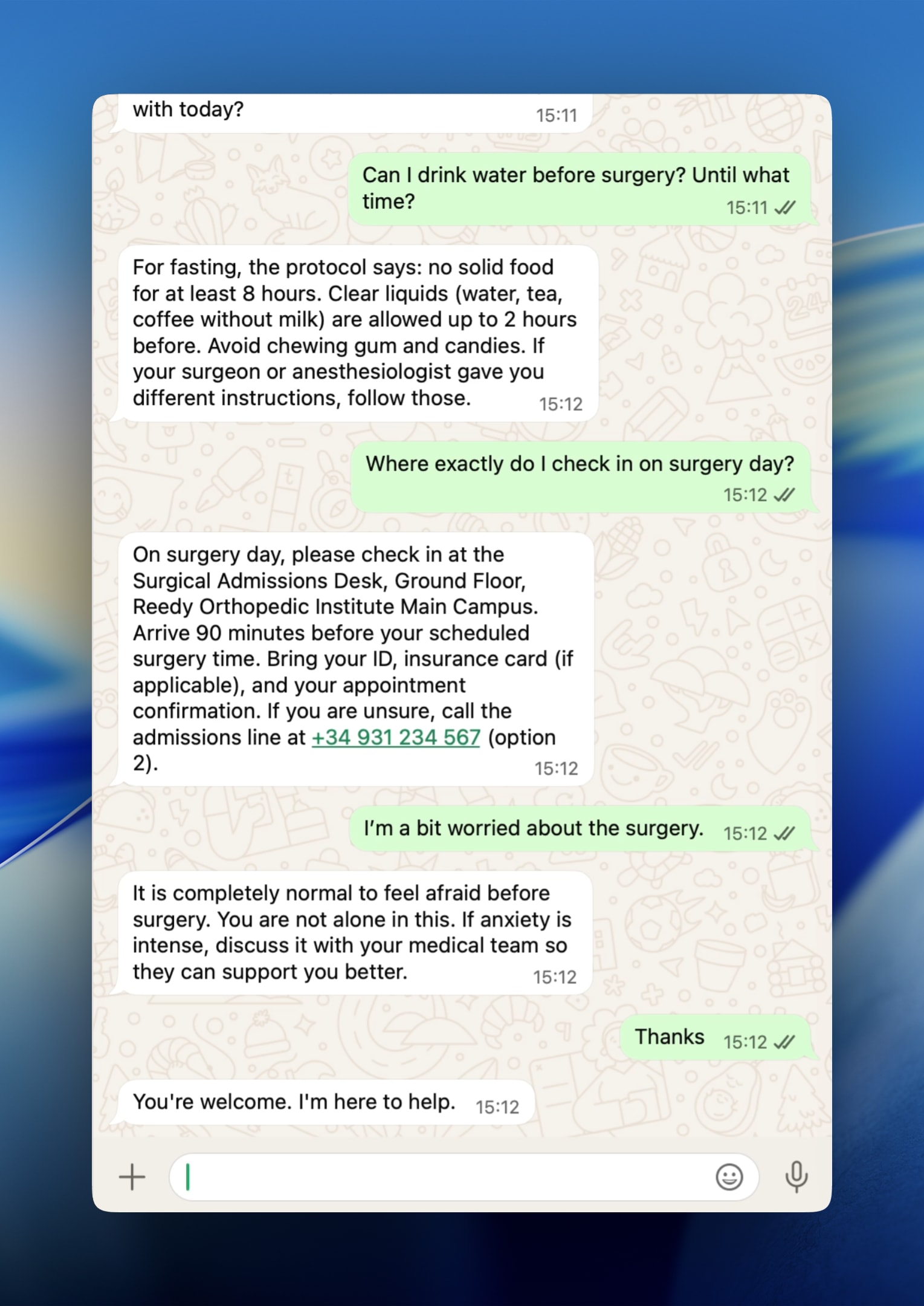
Pacient:
Puc beure aigua abans de la cirurgia? Fins a quina hora?
Agent:
Per al dejuni: no aliments sòlids durant almenys 8 hores abans de la cirurgia. Líquids clars (aigua, te sol, cafè negre) permesos fins a 2 hores abans. No xiclets ni caramel durs ni begudes amb llet després de mitjanit. Si el teu cirurgià et va donar instruccions diferents, segueix-les.
Aquesta barreja —fluïdesa del LLM, context estructurat i gestió explícita de la incertesa— és el que separa un assistent modern d’un FAQ estàtic o un arbre de decisions rígid.
Gestió de preguntes fora d’abast
El valor real no és només el que respon l’assistent, sinó com tracta el que no sap. En pilots petits, sovint n’hi ha prou amb instruccions clares al prompt del sistema. A escala s’afegeixen capes: classificació d’intencions, scores de confiança, monitoratge actiu i bucles de feedback amb escalament humà.
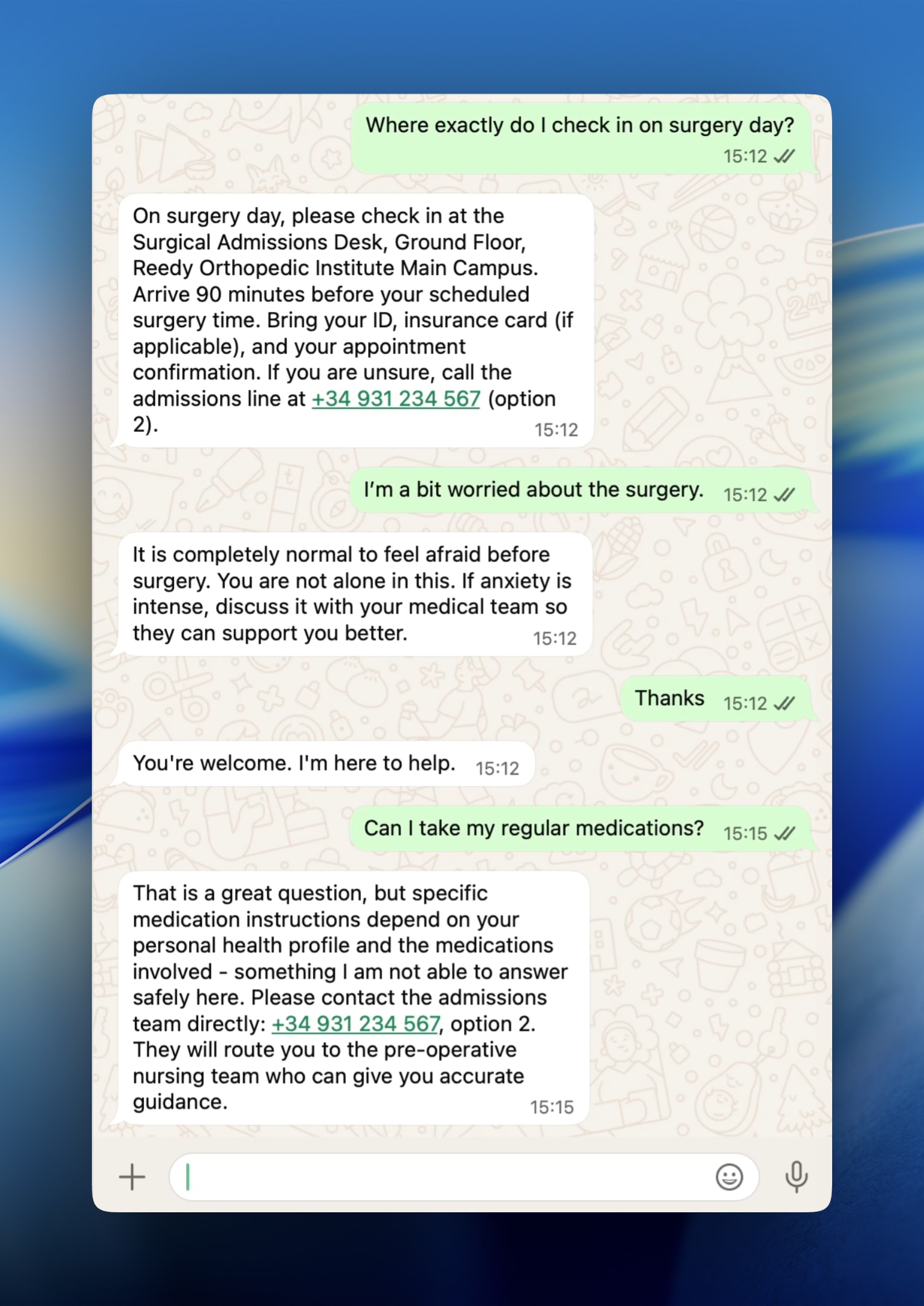
Pacient:
Puc prendre la meva medicació habitual?
Agent:
Bona pregunta, però les instruccions sobre medicació depenen del teu perfil de salut i dels fàrmacs concrets, i aquí no et puc respondre amb seguretat. Contacta amb ingressos: +34 931 234 567, opció 2; et derivaran a infermeria preoperatòria per orientació precisa.
Un assistent que diu «no tinc aquesta informació, truca aquí» és infinitament més valuós que un que endevina.
Arquitectura del sistema
El sistema té quatre components principals: WhatsApp (usuari) → Twilio (webhook HTTPS) → servidor Node.js + Express (sessió + LLM) → resposta via API REST de Twilio cap a l’usuari.
WhatsApp (usuari)
L’usuari envia el missatge.
Twilio Messaging API
HTTPS POST (webhook); reenvia al teu endpoint.
Servidor Node.js + Express
Magatzem de sessions (memòria / Redis), historial per usuari, recuperació des d’una base de coneixement preprocessada (RAG) i crida al LLM amb prompt de sistema més context recuperat.
WhatsApp (resposta)
Twilio lliura el missatge de l’assistent al mateix fil.
- Twilio
Compliment de WhatsApp Business API, números i lliurament. El teu servidor parla amb Twilio, no amb WhatsApp directament.
- Node.js + Express
Rep el webhook, extreu el missatge, recupera l’historial, cerca fragments rellevants en una base de coneixement preprocessada (RAG), crida el LLM i envia la resposta amb el client REST de Twilio.
- Magatzem de sessions
Historial per usuari. Un Map en memòria serveix per al prototip; a producció convé Redis o emmagatzematge persistent amb TTL.
- API del LLM
Prompt de sistema, restriccions i base de coneixement; l’historial viatja com a array de missatges a cada crida.
Implementació: el codi que importa
1. El prompt de sistema: la decisió d’enginyeria més important
El prompt defineix què sap l’agent, com es comporta i què es nega a fer. Nota: en producció avançada, la base de coneixement no sol anar inline: es combina amb RAG, APIs internes, versionat de coneixement i context personalitzat. Si vols accelerar aquest tipus d’implementacions, Reedy ajuda a portar sistemes d’IA conversacional a producció amb un stack RAG avançat.
// prompts/systemPrompt.js
const SYSTEM_PROMPT = `
You are a pre-operative patient assistant for the Reedy Orthopedic Institute.
Your role is to answer patient questions in the 48 hours before elective surgery.
KNOWLEDGE BASE:
- Fasting protocol: no solid food for at least 8 hours before surgery.
Clear liquids (water, plain tea, black coffee) are allowed up to 2 hours before.
No chewing gum, hard candy, or milk-based drinks after midnight.
- Check-in location: Surgical Admissions Desk, Ground Floor, Main Campus.
Arrive 90 minutes before scheduled surgery time.
Required documents: government-issued ID, insurance card (if applicable), appointment confirmation.
Admissions line: +34 931 234 567, option 2.
- Common emotional responses: anxiety before surgery is normal and expected.
Acknowledge the patient's feelings before providing information.
If anxiety is described as severe or debilitating, recommend discussing with the medical team.
BEHAVIOR RULES:
1. Answer only questions you can answer from the knowledge base above.
2. If a question is outside scope, say so clearly and provide the admissions line.
3. Never invent specific medical information not present in the knowledge base.
4. Keep responses concise. Patients read these on a phone screen.
5. If the patient gives different instructions from their surgeon, always defer to the surgeon.
6. Greet the patient by first name on the first message if their name is known from context.
7. Respond in the same language the patient uses.
`;
module.exports = SYSTEM_PROMPT;
Decisions de disseny crítiques
La regla 2 és la vàlvula de seguretat: un agent fonamentat que deriva a humans val més que un que improvisa. No negociable en contextos clínics; bona pràctica gairebé arreu.
La regla 7 permet entrada multilingüe sense lògica extra d’enrutament: el model detecta l’idioma i respon en conseqüència.
2. Gestió de sessions: mantenir el context
MAX_HISTORY_TURNS acota cost i finestra de context: les APIs cobren per token i un historial il·limitat és risc de facturació.
// sessions/sessionStore.js
const sessions = new Map();
const MAX_HISTORY_TURNS = 10; // keep last 10 exchanges to manage context window
function getHistory(userId) {
return sessions.get(userId) || [];
}
function addTurn(userId, role, content) {
const history = getHistory(userId);
history.push({ role, content });
// trim to max turns (each turn = 2 messages: user + assistant)
const maxMessages = MAX_HISTORY_TURNS * 2;
if (history.length > maxMessages) {
history.splice(0, history.length - maxMessages);
}
sessions.set(userId, history);
}
function clearHistory(userId) {
sessions.delete(userId);
}
module.exports = { getHistory, addTurn, clearHistory };
3. Client del LLM: la integració
max_tokens: 512 és intencional: al mòbil, una resposta que obliga a fer scroll és mala UX.
// llm/claudeClient.js
const Anthropic = require('@anthropic-ai/sdk');
const SYSTEM_PROMPT = require('../prompts/systemPrompt');
const client = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY });
async function generateResponse(history, userMessage) {
// append the new user message to history before calling the API
const messages = [
...history,
{ role: 'user', content: userMessage }
];
const response = await client.messages.create({
model: 'claude-sonnet-4-20250514',
max_tokens: 512, // keep responses short for mobile reading
system: SYSTEM_PROMPT,
messages
});
return response.content[0].text;
}
module.exports = { generateResponse };
4. El servidor de webhooks: orquestració
Cal retornar sempre 200 a Twilio, fins i tot en error, per evitar reintents que dupliquin missatges. El bloc catch ha d’enviar un fallback segur cap a un humà. Usa req.body.From tal qual (inclou el prefix whatsapp:) com a clau de sessió i com a destí de resposta.
// server.js
require('dotenv').config();
const express = require('express');
const twilio = require('twilio');
const { getHistory, addTurn } = require('./sessions/sessionStore');
const { generateResponse } = require('./llm/claudeClient');
const app = express();
app.use(express.urlencoded({ extended: false }));
const twilioClient = twilio(
process.env.TWILIO_ACCOUNT_SID,
process.env.TWILIO_AUTH_TOKEN
);
app.post('/webhook', async (req, res) => {
// Twilio sends form-encoded data
const incomingMessage = req.body.Body?.trim();
const fromNumber = req.body.From; // e.g. "whatsapp:+34612345678"
if (!incomingMessage || !fromNumber) {
return res.status(400).send('Missing required fields');
}
try {
// 1. Retrieve conversation history for this user
const history = getHistory(fromNumber);
// 2. Generate response from LLM
const reply = await generateResponse(history, incomingMessage);
// 3. Persist the new turn
addTurn(fromNumber, 'user', incomingMessage);
addTurn(fromNumber, 'assistant', reply);
// 4. Send reply via Twilio
await twilioClient.messages.create({
from: process.env.TWILIO_WHATSAPP_NUMBER,
to: fromNumber,
body: reply
});
// Twilio expects a 200 response even if you send the reply programmatically
res.status(200).send('OK');
} catch (error) {
console.error('Webhook error:', error);
// Send a safe fallback message rather than letting the conversation die
await twilioClient.messages.create({
from: process.env.TWILIO_WHATSAPP_NUMBER,
to: fromNumber,
body: 'We are experiencing a temporary issue. Please call +34 931 234 567 for immediate assistance.'
});
res.status(200).send('OK'); // still 200 to prevent Twilio retry loops
}
});
app.listen(process.env.PORT, () => {
console.log(`Webhook server running on port ${process.env.PORT}`);
});
De prototip a producció: els quatre pilars
- 1. Validació de signatura del webhook
Twilio signa cada petició (HMAC-SHA1). Valida amb twilio.validateRequest(). Sense això, qui descobreixi la URL podria injectar missatges.
- 2. Magatzem de sessions persistent
Substitueix el Map per Redis amb TTL (p. ex. 24 h) per no acumular converses obsoletes.
- 3. Rate limiting
Límits per número (express-rate-limit + Redis) per evitar abús i pics de cost al LLM.
- 4. Logging estructurat i monitoratge
Registra entrades, sortides i errors; evita emmagatzemar el telèfon en clar si no cal. Alertes sobre latència i taxa d’error.
Resultats observats a la implementació real
- 78% de cobertura
Dejuni, check-in i reconeixement d’ansietat van concentrar el 78% del trànsit: una base de coneixement enfocada absorbeix la major part de la càrrega.
- Latència acceptable
Mediana ~2,1 s i p95 ~4,8 s entre webhook i lliurament; raonable per a missatgeria asíncrona.
- 11% de derivació
Consultes enviades a ingressos per estar fora d’abast: per disseny, l’agent no pretén cobrir-ho tot.
- Satisfacció qualitativa
Els pacients van valorar la disponibilitat 24/7, especialment fora d’horari quan puja l’ansietat prequirúrgica.
Casos d’ús en altres indústries
- Retail
Seguiment de comandes, estoc, devolucions.
- Immobiliària
Visites, disponibilitat, preguntes sobre contractes.
- Serveis professionals
Confirmació de cites, preparació de reunions, FAQs.
- Educació i RR. HH.
Recordatoris, materials, polítiques internes — sempre amb grounding i escalament.
La pregunta correcta no és «WhatsApp pot fer això?», sinó «tenim un cos de coneixement del qual un model ben instruït pugui extreure amb fiabilitat?». Si la resposta és sí, el camí tècnic sol ser més curt del que els equips esperen.
Lliçons apreses i recomanacions
Twilio + Node.js + un LLM actual formen un stack viable per a producció en un ampli ventall d’automatització conversacional.
El que determina si l’assistent és útil o perjudicial és: (1) qualitat del prompt de sistema, (2) disciplina de grounding, (3) robustesa del camí de fallada cap a humans.
La implementació mostrada ronda les 150 línies de codi; la complexitat operativa està en desplegament, govern del coneixement i monitoratge, no només a l’app.
Propers passos
1. Quines preguntes repetitives consumeixen temps del teu equip?
2. Tens documentació o coneixement estructurat que les respongui?
3. Hi ha un canal humà clar quan l’automatització no arriba?
Si les tres respostes són sí, el camí tècnic és més curt del que penses.
Construïm junts
Unim experiència i innovació per portar el teu projecte al següent nivell.