Anàlisi de Documents amb LLMs: De l’OCR a la comprensió estructural.
Introducció
Extreure informació útil de documents PDF i fulls de càlcul complexos ha estat, durant anys, un gran desafiament. Eines tradicionals com l’OCR (Reconeixement Òptic de Caràcters) van ser creades per convertir text en imatges escanejades a text pla. Tanmateix, el seu enfocament és limitat: extreuen els caràcters, però perden l’estructura del document, no comprenen jerarquies visuals ni relacions contextuals entre columnes o cel·les.
Per exemple, en processar un estat financer amb un OCR o parser tradicional, una taula de balanç com aquesta:

Pot ser mal interpretada com un llistat lineal o seqüencial de valors, trencant la relació entre cada títol i el seu valor corresponent. Això passa perquè l’OCR no “veu” el layout de la taula, ni sap que “ACTIVO NO CORRIENTE” amb “40.000” i “Inmovilizado intangible” estan en una mateixa columna estructurada, i encara menys que hi ha dos blocs comptables paral·lels en la mateixa línia.
A la pràctica, això genera errors com:
Barreja de columnes d’actius i patrimoni net.
Duplicació o pèrdua d’informació.
Interpretacions incorrectes en intentar convertir-ho en dades utilitzables.
Davant d’aquestes limitacions, els nous models de llenguatge grans (LLMs) i models multimodals introdueixen el concepte de PDF understanding: una manera d’interpretar no només el text, sinó també l’estructura visual i semàntica del document. Eines com LlamaParse utilitzen aquests models per mantenir relacions de columnes, jerarquia visual (títols, subtítols, agrupacions) i context, fins i tot en documents amb estructures mixtes com taules comptables o balanços financers.
Per exemple, en el mateix cas anterior, LlamaParse pot identificar correctament que hi ha dues seccions (Actius vs Patrimoni Net), amb els seus respectius subtítols i imports, preservant la seva distribució original i convertint-ho en una taula estructurada vàlida per a consulta o anàlisi.
Aquest salt tecnològic marca una transició clara: de l’OCR que simplement “llegeix lletres”, al LLM que comprendrà el document com un tot.
LlamaParse i LlamaCloud
L’auge dels models de llenguatge ha generat una nova categoria d’eines especialitzades a transformar documents no estructurats en dades comprensibles per a la intel·ligència artificial. En aquest context, LlamaParse es posiciona com una de les solucions més robustes i versàtils per interpretar PDFs i altres formats complexos. La seva integració a la plataforma LlamaCloud permet escalar aquests processos a nivell empresarial.
LlamaParse és un motor de parsing desenvolupat per LlamaIndex, dissenyat específicament per integrar-se amb models generatius i fluxos de RAG (Retrieval-Augmented Generation).
A diferència dels parsers tradicionals, LlamaParse està optimitzat per extreure text, taules, jerarquia estructural i contingut visual com imatges o diagrames, tot en un format fàcilment digerible pels LLMs.
Admet múltiples tipus de fitxer, entre els quals:
DOCX, PPTX, XLSX
EPUB, HTML, JPEG
Fitxers ZIP amb múltiples documents
A més, ofereix sortida en Markdown enriquit i JSON estructurat, i es pot integrar amb eines com LlamaIndex, LangChain o qualsevol LLM via API.
Exemple
Imaginem que puges un contracte en PDF amb títols com “Clàusula 1: Objecte del contracte” i “Clàusula 2: Obligacions del proveïdor”. Un parser normal pot retornar text pla, sense distingir seccions. LlamaParse, en canvi, et retornarà una estructura jeràrquica com aquesta:
Què és LlamaCloud?
Infraestructura al núvol on viu LlamaParse, dissenyada per oferir:
Processament escalable i asíncron.
Processament per lots.
Gestió de documents i resultats parsejats.
Interfície API i SDKs (CLI, Python).
Compatibilitat amb eines com Neo4j, Snowflake, LangChain i més.
A més, LlamaCloud permet configurar processaments personalitzats: des de formats de sortida fins a puntuacions de confiança per pàgina, correcció d’inclinació, detecció d’idioma i molt més.
Exemple pràctic
Un cas real molt comú és el processament de manuals tècnics PDF amb moltes taules, capçaleres i diagrames. LlamaParse no només extreu el contingut textual, sinó que preserva el disseny de les taules (fins i tot amb cel·les combinades), extreu les imatges com a fitxers separats, i manté les capçaleres jerarquitzades.
Per exemple, un diagrama dins del document serà retornat com:
{
"type": "image",
"description": "Diagrama de flujo del proceso",
"path": "doc_assets/image_2.png"
}
Una taula d’especificacions tècniques es podrà convertir en Markdown o JSON estructurat llest per alimentar un motor de cerca, un agent LLM o una base de dades.
La combinació de LlamaParse + LlamaCloud permet transformar documents complexos en representacions fidels i estructurades, preparades per a tasques com cerca semàntica, RAG, extracció de dades o generació de resums intel·ligents. El seu disseny nadiu per a LLMs marca la diferència enfront de parsers tradicionals que no comprenen el context ni la intenció del document.
Avantatges clau i exemples d’ús
LlamaParse no és només un parser “més modern”, sinó una eina que redefineix com extraiem i fem servir la informació continguda en documents complexos. A continuació, repassem els seus beneficis clau davant d’enfocaments tradicionals, i mostrem com empreses reals ja estan aprofitant la seva potència en diferents sectors.
Avantatges principals
- Preservació d’estructura i jerarquia
A diferència dels parsers tradicionals que retornen text pla, LlamaParse conserva la jerarquia visual i lògica del document: títols, subtítols, llistes, taules, peus d’imatge i més.
Exemple: En un manual tècnic, les capçaleres com1. Introducció,1.1 Abasti1.2 Limitacionssón convertides en Markdown amb la indentació apropiada, permetent cerques contextuals o navegació amb LLMs. - Gestió avançada de taules
LlamaParse interpreta correctament taules amb múltiples capes de capçaleres, cel·les fusionades, subtotals i formats mixtos (nombres, dates, text).
Exemple: En un balanç financer com el que hem compartit, LlamaParse pot identificar que “A) Actiu no corrent” i “A) Patrimoni net” pertanyen a columnes diferents, i que “0,00” està correctament alineat amb la seva categoria comptable, sense barrejar dades. - Extracció multimodal (text + imatges)
Extreu imatges, diagrames i gràfics del document, generant metadades útils com descripció, posició i relació amb el text.
Exemple: En una presentació en PDF, cada diagrama pot ser desat com a fitxer `.png` vinculat al seu peu de figura, permetent-ne l’ús separat o la interpretació per un model de visió. - Llest per a LLMs
La sortida (en Markdown, JSON o XML) està optimitzada per alimentar models generatius, motors de RAG, embeddings, agents o fluxos d’extracció automatitzada.
Exemple: Una clàusula legal extreta per LlamaParse pot usar-se directament en una pregunta a un LLM: “En quina clàusula del contracte es menciona el període de cancel·lació?”, i la resposta inclourà un fragment precís, amb referència a la secció correcta.
Casos d’ús per sector
- Finances i comptabilitat
Parsing de balanços, informes anuals i factures. Extracció de KPIs i comparació de mètriques entre documents.
- Legal i compliance
Ingesta massiva de contractes amb extracció de clàusules clau (dates, obligacions, penalitzacions). Creació de cercadors semàntics per a revisió de documents legals.
- Recursos Humans
Extracció de dades des de CVs, formularis d’avaluació, fulls de vida. Generació de resums de candidats o detecció de requisits clau.
- R+D i documentació tècnica
Processament de papers, manuals, patents i informes científics. Construcció de grafs de coneixement o cerca per contingut tècnic.
Errors comuns i estratègies d’implementació
Tot i que LlamaParse facilita enormement l’extracció d’informació de documents, la seva implementació no està exempta de reptes. Moltes organitzacions, en integrar aquest tipus de solucions, ensopeguen amb errors comuns que poden afectar la qualitat dels resultats o l’eficiència del flux de treball. A continuació, repassem els més freqüents i les millors pràctiques per evitar-los.
Errors comuns
- Subestimar la complexitat del conjunt de dades
Algunes empreses intenten processar tot el seu repositori documental d’una sola vegada sense auditar prèviament el tipus de documents. Això sol provocar inconsistències en els resultats.
Exemple: Una asseguradora carrega formularis, contractes i informes mèdics en el mateix lot, esperant una sortida homogènia. El resultat és una barreja de formats i pèrdua de precisió en certs tipus de documents. - Ignorar el layout i la jerarquia
Tot i que LlamaParse preserva l’estructura, si no es configura la sortida adequada (Markdown vs JSON, per exemple), es corre el risc d’obtenir resultats difícils d’explotar.
Exemple: Un balanç financer extret en text pla perd les relacions entre columnes, mentre que configurat en JSON preserva cada bloc amb la seva etiqueta comptable correcta. - No establir validacions de qualitat
En confiar cegament en el parser, es corre el risc d’utilitzar dades incorrectes. LlamaParse ofereix puntuacions de confiança per pàgina, però moltes vegades no s’apliquen.
Exemple: Un document escanejat amb baixa qualitat és processat sense revisió. Després, un LLM dona respostes basades en dades incompletes, afectant la presa de decisions. - Processar per lots sense control d’errors
Quan es pugen centenars de documents en paral·lel, una fallada en un pot aturar tot el procés si no s’apliquen bones pràctiques de resiliència.
Exemple: En una auditoria legal, si un sol contracte genera error, el sistema pausa tota l’execució en lloc de processar la resta.
Estratègies recomanades
- Fase d’auditoria inicial
Identificar quins documents aporten més valor al parseig i quins són més complexos (p. ex., balanços, contractes, manuals tècnics). Això permet prioritzar i optimitzar.
- Pilots controlats
Començar amb un conjunt petit de documents per provar configuracions (Markdown, JSON, XML) i validar que la sortida sigui útil per al cas d’ús.
- Ús de puntuacions de confiança
Configurar alertes o revisions humanes en pàgines amb puntuació baixa, reduint errors crítics en dades sensibles.
- Processament per lots amb recuperació
Utilitzar la infraestructura de LlamaCloud per processar documents en paral·lel, amb checkpointing i reintents automàtics en cas de fallades.
- Cicles de retroalimentació
Integrar revisions manuals i feedback loops per millorar contínuament el parsing i adaptar configuracions segons els documents més freqüents.
Exemple pràctic 1: Parsing de dades financeres en PDF i Excel
Un dels escenaris més comuns on les solucions tradicionals d’OCR fallen és en l’extracció d’informació financera des de documents PDF escanejats o taules comptables en Excel. En aquest tipus d’arxius, l’estructura tabular és crítica: no n’hi ha prou amb llegir els números, sinó que cal mantenir la relació entre cada concepte i el seu import corresponent.
El repte amb OCR tradicional
- Pèrdua de dades
Alguns imports no van ser detectats, especialment quan estaven alineats a la dreta.
- Errors de caràcters
Es van introduir xifres inexistents (p. ex., llegir “80.000” com “80000l”).
- Salts de línia incorrectes
Files de taules partides en dos, cosa que trencava la coherència entre el títol i el seu valor.
- Desalineació de columnes
Conceptes de l’“Actiu” barrejats amb imports del “Passiu”.
Exemple amb OCR (Tesseract)
El resultat és un text pla, ple d’errors i sense una estructura fiable.
Parsing amb LlamaParse
En contrast, en processar el mateix document amb LlamaParse, es van obtenir resultats estructurats i jeràrquics, preservant el format tabular i eliminant els errors de l’OCR.
Exemple amb LlamaParse (sortida en Markdown):
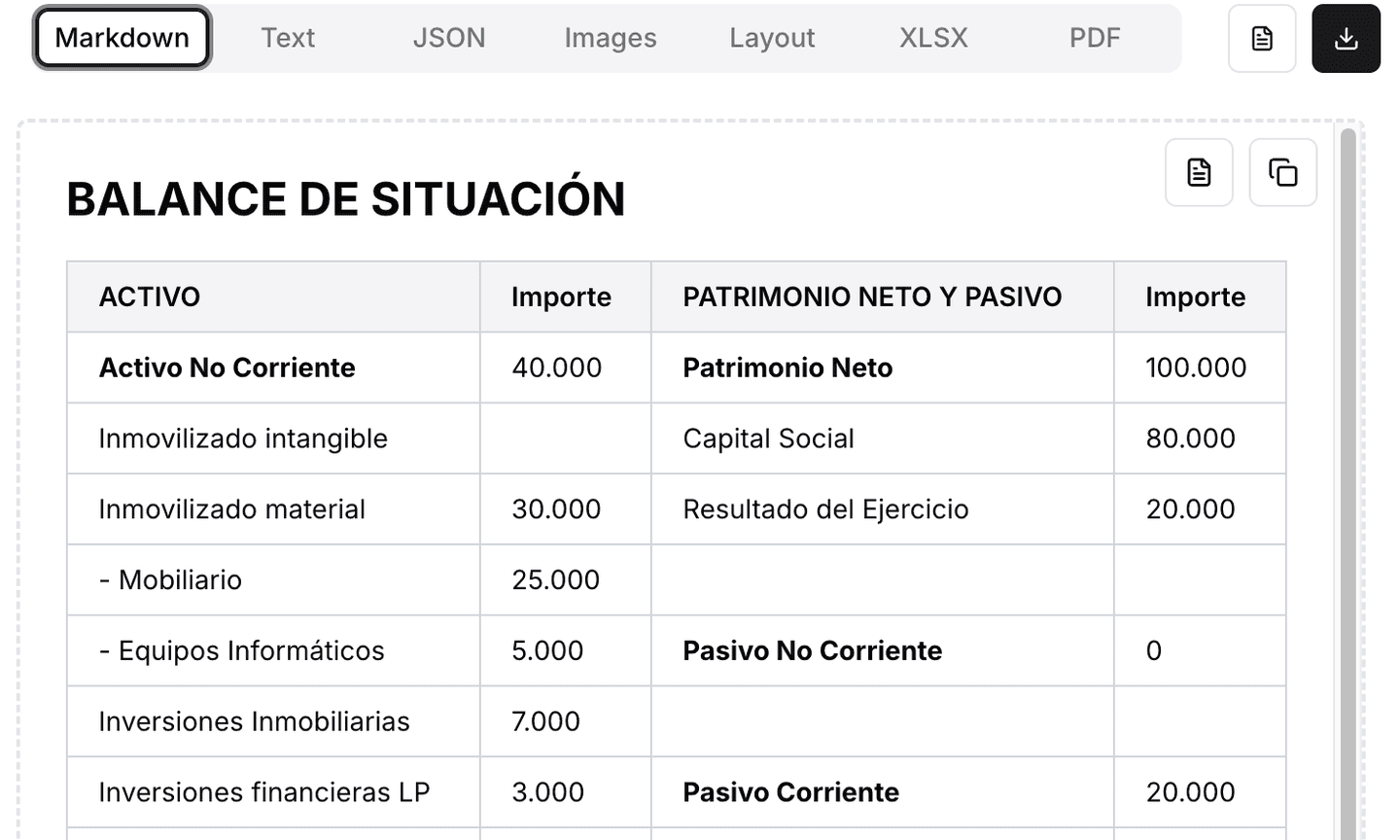
Beneficis observats
Preservació de la jerarquia: es diferencien clarament seccions, subtotals i conceptes.
Taules interpretades correctament: es va mantenir la relació entre columnes d’“Actiu” i “Passiu”.
Zero errors de caràcters: els imports es van extreure fidelment.
Format usable directament: la sortida en Markdown o JSON pot connectar-se a un motor de cerca, un dashboard financer o una base de dades.
Conclusió del cas
Mentre que l’OCR tradicional genera un text pla sorollós i difícil d’explotar, LlamaParse retorna una estructura fidel al document original, llesta per ser utilitzada en fluxos d’anàlisi financera, auditoria o consulta amb LLMs.
Exemple pràctic 2: Manual de reparació (text + imatges + diagrames)
En manuals tècnics escanejats és habitual que l’OCR “desenganxi” el text de les seves figures: les fotos queden sense peu, els passos es barregen i els diagrames es perden. En el nostre cas, el problema més gran va ser associar cada imatge de la reparació amb la seva descripció.
Amb LlamaParse, vam resoldre dues coses simultàniament:
Extracció d’imatges com a fitxers individuals (p. ex., `page_03_fig_02.png`).
Generació de descripcions/alt-text i vinculació de cada imatge amb el pas i el peu de figura.
Què falla amb OCR tradicional (abans)
Imatges no extretes o sense noms útils.
Peus de figura (“Fig. 2 – Retirar tapa posterior”) queden com a text solt.
Pèrdua de l’ordre: el “Pas 3” pot acabar lluny de la seva foto.
Sortida típica (OCR):
Què retorna LlamaParse (després)
LlamaParse manté el context visual i l’ordre, i a més pot crear una representació estructurada (JSON/Markdown) on cada pas referencia explícitament la seva imatge.
Exemple de sortida (JSON) simplificat:
{
"document_title": "Manual de reparación - Lavadora X200",
"sections": [
{
"title": "Desmontaje",
"steps": [
{
"step_number": 3,
"text": "Retire la tapa trasera retirando 4 tornillos Phillips.",
"figure_ref": "Fig. 2",
"image": {
"path": "assets/page_03_fig_02.png",
"alt": "Vista posterior de la lavadora con tapa trasera y ubicación de 4 tornillos Phillips",
"page": 3,
"bbox": [128, 244, 612, 531]
}
},
{
"step_number": 4,
"text": "Desconecte la manguera de desagüe del conjunto de la bomba.",
"figure_ref": "Fig. 3",
"image": {
"path": "assets/page_04_fig_03.png",
"alt": "Detalle de la manguera de desagüe conectada a la bomba de agua",
"page": 4,
"bbox": [96, 210, 580, 500]
},
"warnings": [
"Asegúrese de cerrar la válvula de agua antes de desconectar la manguera."
]
}
]
}
]
}
Què aporta això:
step_number i figure_ref asseguren la relació pas–figura.
image.path et retorna el fitxer retallat llest per a UI o informes.
alt és la descripció generada (útil per a accessibilitat i cerca).
page i bbox (posició) permeten grounding i validacions visuals.
Variant en Markdown (llista de passos amb imatges)
Flux recomanat (resum)
Puja el PDF escanejat del manual a LlamaParse.
Configura la sortida JSON (per a estructura) o Markdown (per a docs/UI).
Habilita extracció d’imatges i descripcions (alt-text).
Utilitza els camps page/bbox per validar visualment o construir previews.
Integra el JSON a la teva aplicació: renderitza cada pas amb la seva imatge i advertiments.
Beneficis observats
Associació pas–imatge fiable (s’evita el “despreniment” típic de l’OCR).
Accessibilitat i cercabilitat gràcies a l’alt-text generat.
Traçabilitat total: pots tornar a la pàgina exacta i regió on apareix la imatge.
Llest per a RAG: “Mostra’m el pas on es retira la tapa posterior i la seva foto”.
De l’extracció al RAG: emmagatzematge, embeddings i chunking jeràrquic
Un cop processat el document amb LlamaParse, no només comptem amb el text extret, sinó també amb una representació rica en estructura, imatges i metadades. Aquest material és la base per construir pipelines de Retrieval-Augmented Generation (RAG), ja que permet organitzar la informació en unitats consultables i optimitzar tant la recuperació com la generació.
Què tenim tras LlamaParse
Text estructurat (Markdown/JSON) amb seccions, taules i passos.
Imatges extretes (fitxers) + descripcions/alt-text + (opcional) posició (page, bbox).
Metadades (títol, encapçalaments H1/H2…, figure_ref, tipus de bloc, etc.).
Esquema d’emmagatzematge recomanat
{
"doc_id": "manual_x200_v1",
"title": "Manual de reparación - Lavadora X200",
"source": "s3://bucket/manuales/x200.pdf",
"created_at": "2025-08-28",
"doctype": "manual|balance|contrato"
}
{
"chunk_id": "manual_x200_v1#sec1#step3",
"doc_id": "manual_x200_v1",
"hierarchy": ["Desmontaje", "Paso 3"],
"text": "Retire la tapa trasera retirando 4 tornillos ...",
"tables": [],
"images": [
{
"path": "assets/page_03_fig_02.png",
"alt": "Vista posterior de la lavadora...",
"page": 3,
"bbox": [128,244,612,531]
}
],
"metadata": {
"page": 3,
"figure_ref": "Fig. 2",
"block_type": "step",
"layout": "single-column"
}
}
c) Emmagatzematges típics
Text/JSON: base de dades documental (MongoDB), o fitxers en S3/GCS amb índex en SQL.
Imatges: object storage (S3/GCS/Azure Blob) desant només la ruta als chunks.
Vectors: base de dades vectorial (FAISS/pgvector/Pinecone/Weaviate/Qdrant). Desa:
- embedding_text (obligatori)
- embedding_table (opcional, si serialitzes taules)
- embedding_image (opcional, si fas RAG multimodal)
- metadata (doc_id, pàgina, encapçalaments, figure_ref, tipus de bloc, etc.)
7.3. Com vectoritzar? (text, taules, imatges)
Text: Embeddings de frases/paràgrafs. Mida de chunk òptima: 300–800 tokens amb solapament 10–20%. Inclou context jeràrquic en el text a vectoritzar: “[Manual X200 > Desmuntatge > Pas 3] Retiri la tapa…”.
Taules: No aplanis files a l’atzar. Serialitza per fila o bloc lògic (CSV/Markdown fidel + títol + notes), o crea un embedding resum schema+values.
Imatges:
1) Text-first (simple): fes servir l’alt-text generat per LlamaParse, vectoritza’l i desa la ruta de la imatge.
2) Multimodal (avançat): crea embeddings d’imatge (CLIP/LLM-vision) i desa un vector d’imatge a més de l’alt-text.
7.4. Chunking amb jerarquia (crític per a bones respostes)
Respectar l’estructura: un chunk mai no ha de barrejar seccions heterogènies.
Unitats semàntiques: Manual → cada pas + la/les seves figures. Balanç → blocs comptables (sub-chunks si són extensos).
Context jeràrquic inclòs en el text del chunk (ruta de molles de pa).
No trencar taules per la meitat (evita partir una fila).
Solapament moderat (10–20%) per mantenir continuïtat sense redundància excessiva.
Flux de consulta (RAG) recomanat
Consultes híbrides: keyword + vector (BM25/SQL + embeddings).
Reranking: passar els top-k candidats a un reranker (opcional).
Context builder jeràrquic: ajunta chunks germans/pares si el prompt ho requereix; per a taules, afegeix capçaleres i notes.
Resposta citada i amb grounding: retorna text + rutes d’imatges (i page/bbox si aplica). Per a balanços: conserva unitats i format numèric (punts/milers, comes/decimals).
Mini-snippets (orientatius)
from sentence_transformers import SentenceTransformer
import faiss, numpy as np
model = SentenceTransformer("all-MiniLM-L6-v2")
docs = [
{
"chunk_id": "manual_x200_v1#sec1#step3",
"text": "[Manual X200 > Desmontaje > Paso 3] Retire la tapa trasera...",
"image_alt": "Vista posterior de la lavadora..."
},
{
"chunk_id": "balance_2024#activo_corriente#existencias",
"text": "[Balance 2024 > Activo Corriente > Existencias] Mercaderías: 40.000",
"image_alt": None
}
]
texts = [d["text"] for d in docs] + [d["image_alt"] for d in docs if d["image_alt"]]
emb = model.encode(texts, normalize_embeddings=True)
index = faiss.IndexFlatIP(emb.shape[1])
index.add(np.array(emb, dtype="float32"))
Esquema de metadades (desar junt amb cada vector)
{
"chunk_id": "manual_x200_v1#sec1#step3",
"doc_id": "manual_x200_v1",
"headers": ["Desmontaje", "Paso 3"],
"image_paths": ["assets/page_03_fig_02.png"],
"page": 3,
"figure_ref": "Fig. 2",
"block_type": "step"
}
L’extracció “cega” de text ha deixat de ser suficient. Al llarg de l’article hem vist com el PDF understanding basat en LLMs i, en particular, LlamaParse sobre LlamaCloud, transforma documents complexos en dades estructurades i fiables: respecta el layout, entén la jerarquia i relaciona correctament taules, figures i text.
Finances (balanços): LlamaParse va preservar les relacions entre columnes i subtotals, evitant els errors i salts de línia típics de l’OCR (Tesseract). Resultat: dades fidels i llestes per a anàlisi o consulta.
Manual tècnic (rentadores): vam resoldre el problema crític d’associar cada pas amb la seva imatge. LlamaParse va extreure fitxers gràfics, va generar descripcions i va mantenir vincles pas↔figura, habilitant cerques i respostes amb evidència visual.
Després de l’extracció, el valor es consolida amb una canalització de RAG ben dissenyada:
Emmagatzematge de text/JSON, taules i imatges (object storage) amb metadades.
Embeddings de text (i opcionalment de taules i imatges) per a recuperació híbrida.
Chunking jeràrquic (seccions→subseccions→passos/files) amb context i solapament moderat.
Construcció de context amb grounding (pàgina/bbox) i retorn de cites i imatges.
Lliçons clau
El layout importa: no aplanis taules ni barregis blocs heterogenis.
La jerarquia mana: els chunks han de reflectir l’estructura del document.
La multimodalitat suma: alt-text + imatge millora accessibilitat, cerca i traçabilitat.
La qualitat es governa: fes servir puntuacions de confiança, revisions humanes selectives i monitoratge.
En síntesi, passar de l’OCR als LLMs no és només millorar la lectura: és habilitar respostes precises, citables i accionables sobre documents abans opacs. Amb LlamaParse + bones pràctiques de RAG, qualsevol organització pot convertir els seus PDFs en una font viva de coneixement.
Construïm junts
Unim experiència i innovació per portar el teu projecte al següent nivell.