Extract useful information from your data or content with AI.
What is the RAG framework
The RAG (Retrieval-Augmented Generation) framework is an advanced method used in AI to enhance the way it understands and responds to questions.
Imagine AI as a librarian who not only knows a lot, but also knows exactly where to find specific information in a vast library. In the RAG framework, when you ask a question, the AI first acts as a “retrieval,” scanning through vast amounts of data to find relevant information, much like a librarian searching for books that could contain the answer.
Once it gathers this information, it shifts to a “generator” mode, where it combines and processes the gathered data to provide a comprehensive and accurate response, akin to the librarian summarizing the key points from various books.
This two-step process allows the AI to provide more detailed, accurate, and contextually relevant answers, making it particularly useful in scenarios where precise and thorough responses are required.
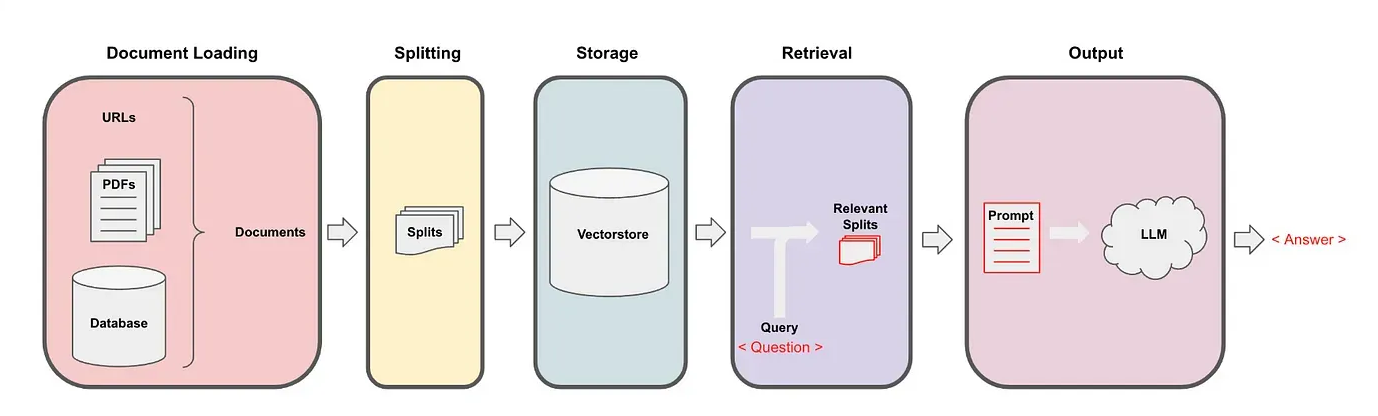
Project description
This project aims to showcase the application of the Retrieval-Augmented Generation (RAG) framework to enhance the retrieval and presentation of information from the AstroJS framework documentation.
Our source of data for this example will be the Astro Framework documentation. With LangChain we are going to access AstroJS documentation, load it, preprocess and transform it into embeddings (OpenAI). Subsequently, we will save the embeddings in a local store (ChromaDB). We then will access the embeddings using LangChain and recover the texts based on the question the user has prompted.
Project setup
Requirements
chromadb
langchain
python-dotenv
bs4
tiktoken
streamlit
streamlit-chat# In this folder we will have all the content of the documentation we want to use
# I have stored here all th .hmlt files here
# since we fdont want to make a lot of requests to the astro server each time we run the program.
Getting Started 🚀 Astro Documentation.html
Install Astro with the Automatic CLI 🚀 Astro Documentation.htmlDocument load
Our first method will be for loading the sources documents. This method will load and parse all the links in the file, so we can pass it to the next phase.
LangChain’s document loaders specialize in importing and transforming data from diverse sources and formats into a uniform structure. They are capable of processing data from a range of origins, including both structured and unstructured environments, such as online platforms, databases, and various proprietary and commercial services. These loaders are compatible with several file types, including documents, spreadsheets, and presentations. They convert these varied data inputs into a consistent document format, complete with content and relevant metadata.
LangChain offers an extensive collection of over 80 different document loaders we can choose based on our content, as seen in their Document Loaders page:https://python.langchain.com/docs/integrations/document_loaderswith the full code. Open it, run the cells, and modify the query to test your own search scenarios.
def load_sources(self):
docs = []
if not os.path.exists('./sources'):
raise ValueError("The specified directory does not exist")
# Construct the search pattern
search_pattern = os.path.join('./sources', '*.html')
# Use glob to find all files that match the pattern
html_files = glob.glob(search_pattern)
for source in html_files:
docs.extend(BSHTMLLoader(source).load())
self.sources = docsDocument splitting
Next, we need to split the document in chunks.
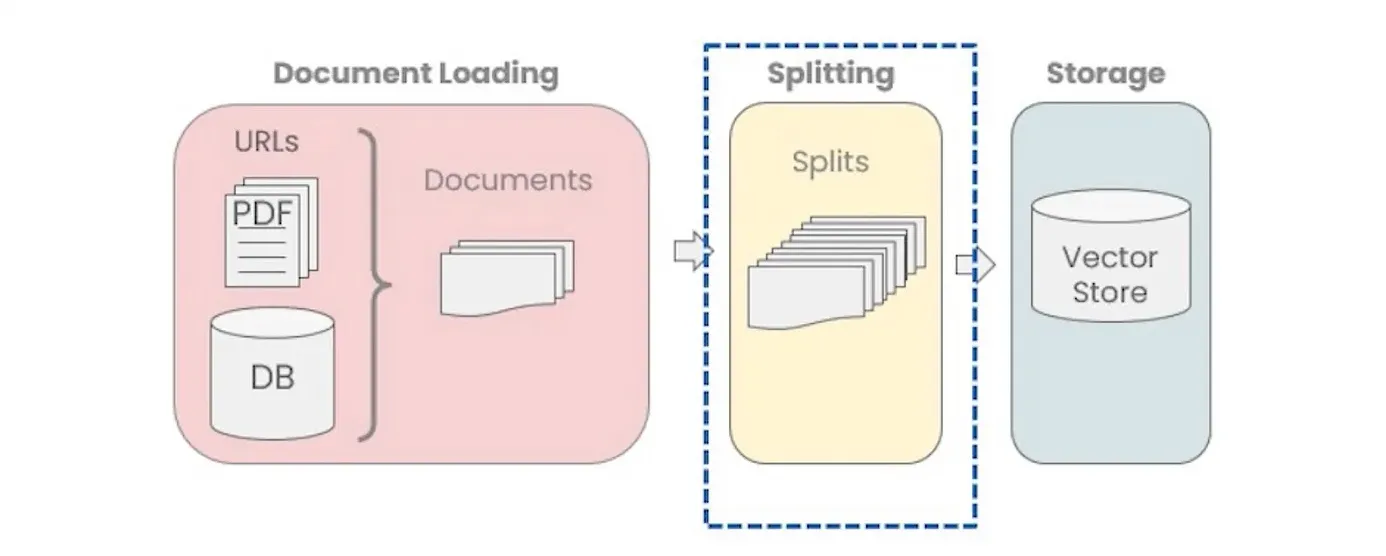
In database management, particularly with vector operations, processing and storing large documents can be resource-intensive.
Splitting these documents into smaller chunks enhances manageability and efficiency. This approach significantly reduces computational complexity and memory usage, making data handling more streamlined and effective.
Smaller vectors, derived from these segments, are easier and faster to process, optimizing both speed and resource utilization in the database system.
def split_documents(self):
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
separators=["
", "
", "(?<=. )", " ", ""]
)
self.splits = splitter.split_documents(self.sources)Vector Stores and Embeddings
After splitting a document into smaller chunks, we need to index them for easy retrieval during question-answering. For this, LangChain utilizes embeddings and vector stores.
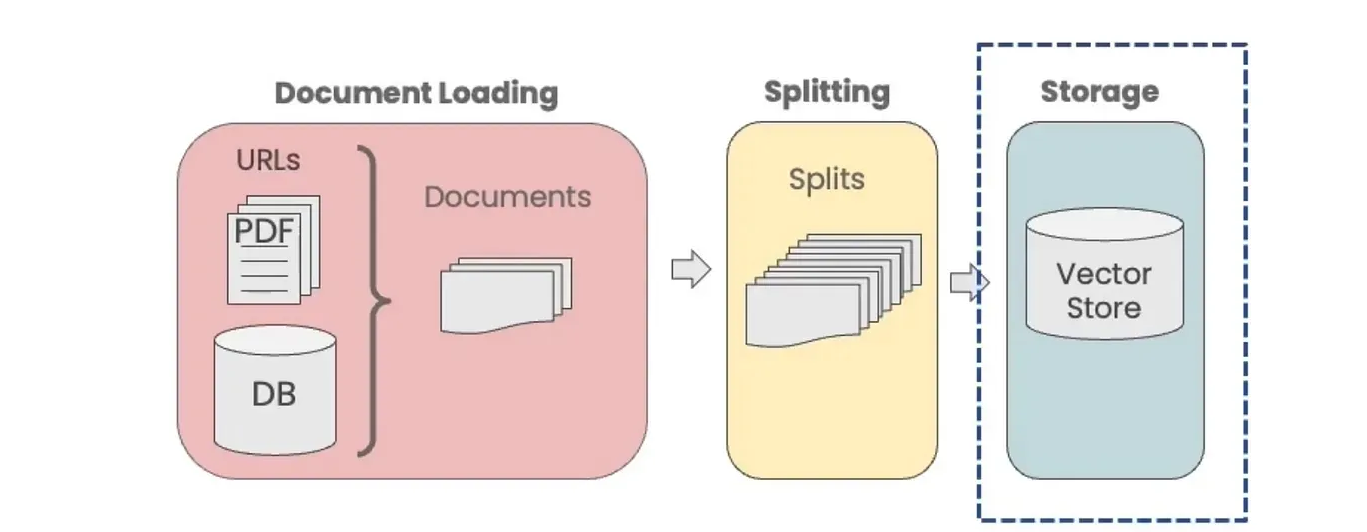
In our case, we will use the MMR technique.
def init_qa_retrieval(self):
self.retrieval = RetrievalQA.from_chain_type(
llm=OpenAI(),
chain_type="map_reduce",
retrieval=self.vector_store.as_retrieval(
search_type="mmr"
)
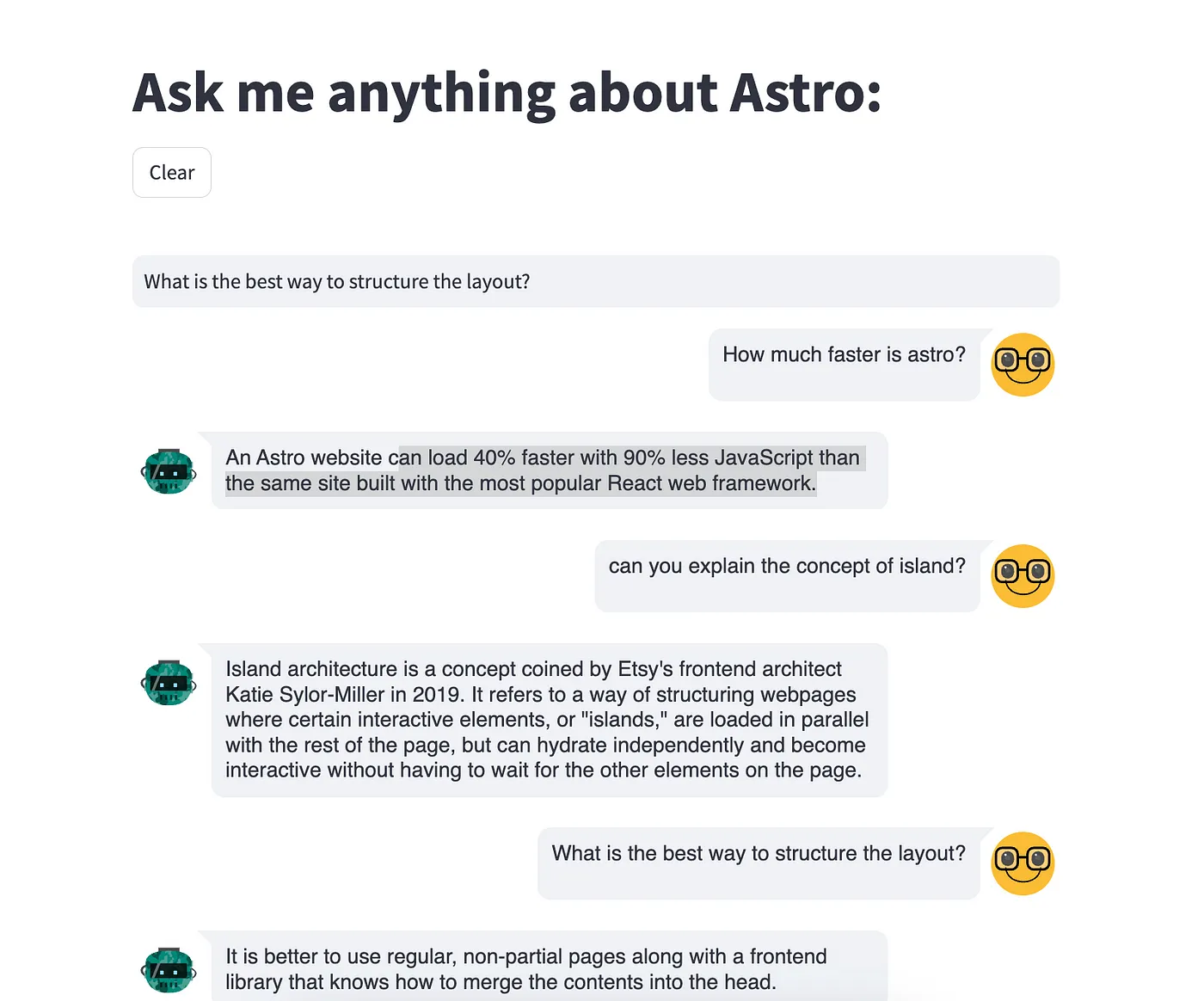
)The resulting UI will look like this:
Other Use Cases
Each of these use cases demonstrates the versatility of the RAG framework in processing and generating valuable insights across diverse domains.
- Customer Support Automation
RAG can be instrumental in enhancing customer support systems. By retrieving and analyzing previous customer queries and resolutions, the framework can generate informed responses to new customer inquiries. This application improves response accuracy and speed, significantly enhancing the customer experience.
- Product Recommendation Systems
In e-commerce, RAG can be utilized to refine product recommendation engines. By evaluating a user’s browsing and purchase history, the system can retrieve relevant product information and generate personalized product suggestions, thereby increasing the likelihood of customer satisfaction and sales.
- Medical Diagnosis Assistance
In healthcare, RAG can assist in diagnosing diseases by analyzing patient symptoms and medical history. By retrieving and processing vast amounts of medical data and research, it can generate potential diagnoses, aiding healthcare professionals in making more informed decisions.
- Legal Document Analysis
For legal professionals, RAG can be used to analyze and summarize lengthy legal documents. By retrieving relevant legal precedents and articles, it can generate concise summaries or highlight key legal points in complex documents, saving time and enhancing the efficiency of legal research.
Conclusion
In summary, with AI’s advanced capabilities, coupled with the robust structure of the RAG framework, businesses can achieve a new level of insight and efficiency. This combination is key in navigating the complexities of today’s data-driven landscape, enabling smarter decision-making and fostering innovation.
If this intersection of AI and the RAG framework sparks your interest, especially in how it can be applied to your data sets, don’t hesitate to get in touch with us. We’re excited to discuss how these cutting-edge tools can be custom-fitted to your business needs, transforming your data into a powerhouse of strategic value.
Let’s build together
We combine experience and innovation to take your project to the next level.