Cómo Construir un Asistente de IA para WhatsApp
De la Idea a Producción
El problema real que resolvimos
Un instituto ortopédico nos contactó con un problema concreto: las enfermeras prequirúrgicas dedicaban horas a las mismas preguntas por teléfono. «¿Puedo beber agua antes de la cirugía?», «¿Dónde debo presentarme?», «¿Puedo tomar mis medicamentos habituales?». Consultas repetidas, cientos de veces al mes, en las 48 horas previas a cada intervención programada.
La solución obvia era automatizar, pero no con un chatbot de reglas fijas que nadie usa, sino con un asistente conversacional inteligente que entiende contexto, responde en lenguaje natural y, sobre todo, sabe cuándo no debe responder.
Este artículo documenta cómo lo construimos, qué aprendimos y por qué esta arquitectura sirve a cualquier empresa que quiera automatizar conversaciones en WhatsApp sin perder calidad ni control.
Por qué WhatsApp (y por qué ahora)
WhatsApp supera los 2.000 millones de usuarios activos. En España y Latinoamérica no es «una opción de mensajería»: es el canal por defecto. Los pacientes confirman citas por WhatsApp; los clientes preguntan por pedidos; el personal coordina turnos.
Durante años, integrar automatización en ese canal implicaba contratos enterprise, plataformas complejas o soluciones frágiles. Eso cambió cuando Twilio democratizó el acceso a la WhatsApp Business API con un modelo simple de webhooks.
Combinado con modelos de lenguaje actuales (Claude, GPT-4), la barrera para lanzar un asistente conversacional útil es lo bastante baja como para que un equipo pequeño pueda llevar una implementación a producción en días, no en meses.
El caso de estudio: un asistente prequirúrgico
Desarrollamos un piloto para el sector sanitario: un asistente que atiende las consultas más frecuentes antes de cirugía, sin costes de plataforma enterprise ni la rigidez de los chatbots tradicionales.
No es
Un chatbot de reglas con caminos predefinidos.
Un asistente general sin límites de alcance.
Una IA que inventa respuestas.
Una plataforma propietaria costosa.
Sí es
Un agente conversacional con contexto acotado.
Una solución técnicamente simple y económicamente viable.
Un sistema con historial de conversación por usuario.
Una arquitectura que fundamenta las respuestas en conocimiento de dominio.
El principio fundamental: grounding
La restricción clave es el grounding: el modelo solo responde a lo que puede sustentar con el contexto proporcionado. Si la pregunta está fuera de alcance, el asistente reconoce el límite y deriva al canal humano adecuado.
Esto no es una limitación, es la característica principal. En un entorno clínico, un agente que inventa es peor que no tener agente. En cualquier industria, es preferible decir «no lo sé, contacta con X» a dar información incorrecta.
Ejemplo de conversación
En el piloto, el asistente respondió sobre protocolos de ayuno y logística de check-in con precisión, citando la base de conocimiento y cerrando con cláusulas de seguridad (por ejemplo, recordar que si el cirujano dio otras instrucciones, prevalecen las del cirujano).
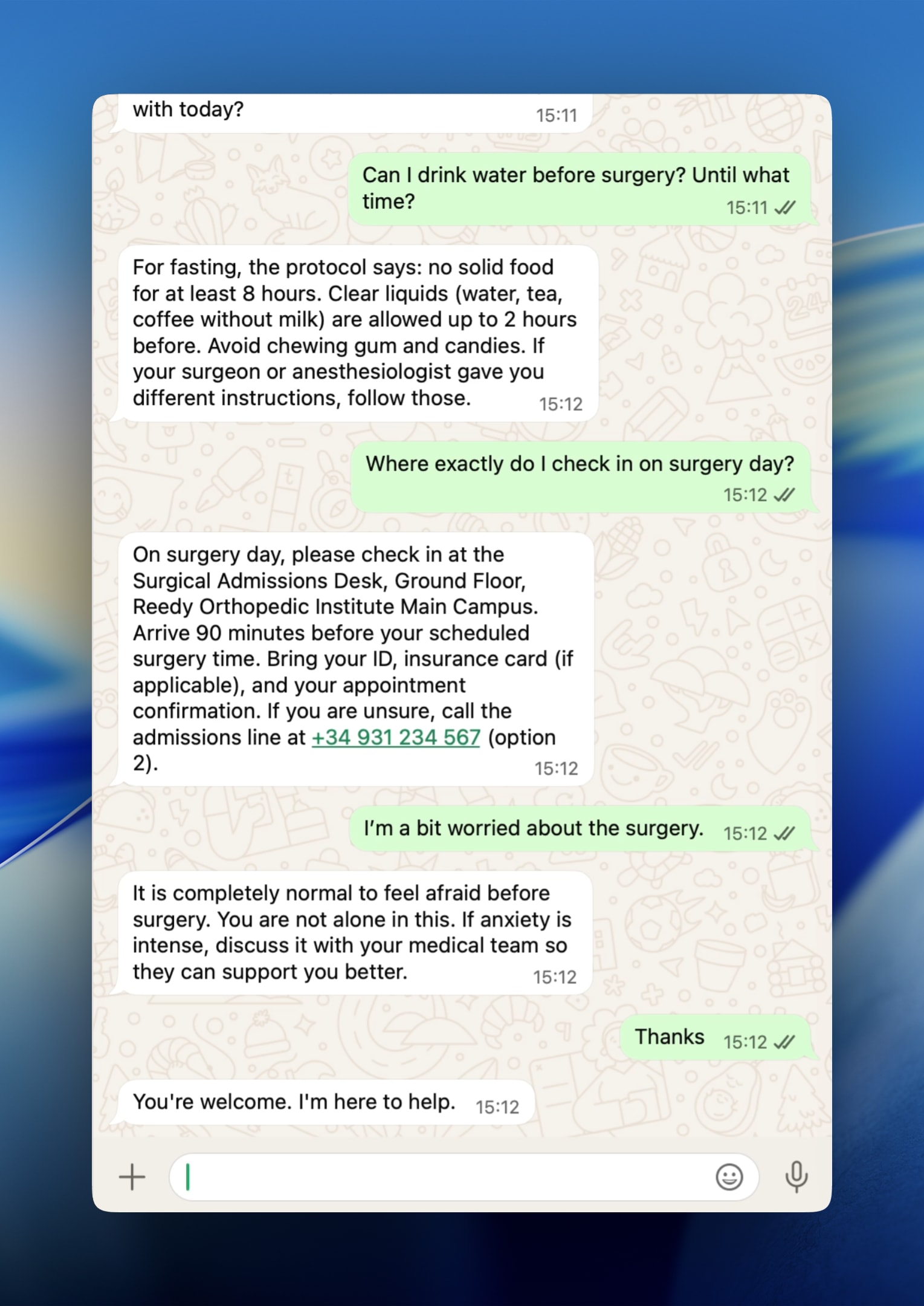
Paciente:
¿Puedo beber agua antes de la cirugía? ¿Hasta qué hora?
Agente:
Para el ayuno: no alimentos sólidos durante al menos 8 horas antes de la cirugía. Líquidos claros (agua, té solo, café negro) permitidos hasta 2 horas antes. No chicles ni caramelos duros ni bebidas con leche después de medianoche. Si tu cirujano te dio instrucciones distintas, sigue esas.
Esa mezcla —fluidez del LLM, contexto estructurado y manejo explícito de la incertidumbre— es lo que separa un asistente moderno de un FAQ estático o un árbol de decisiones rígido.
Manejo de preguntas fuera de alcance
El valor real no está solo en lo que responde el asistente, sino en cómo trata lo que no sabe. En pilotos pequeños, suele bastar con instrucciones claras en el prompt del sistema. A escala, se añaden capas: clasificación de intenciones, scores de confianza, monitorización activa y bucles de feedback con conversaciones escaladas a humanos.
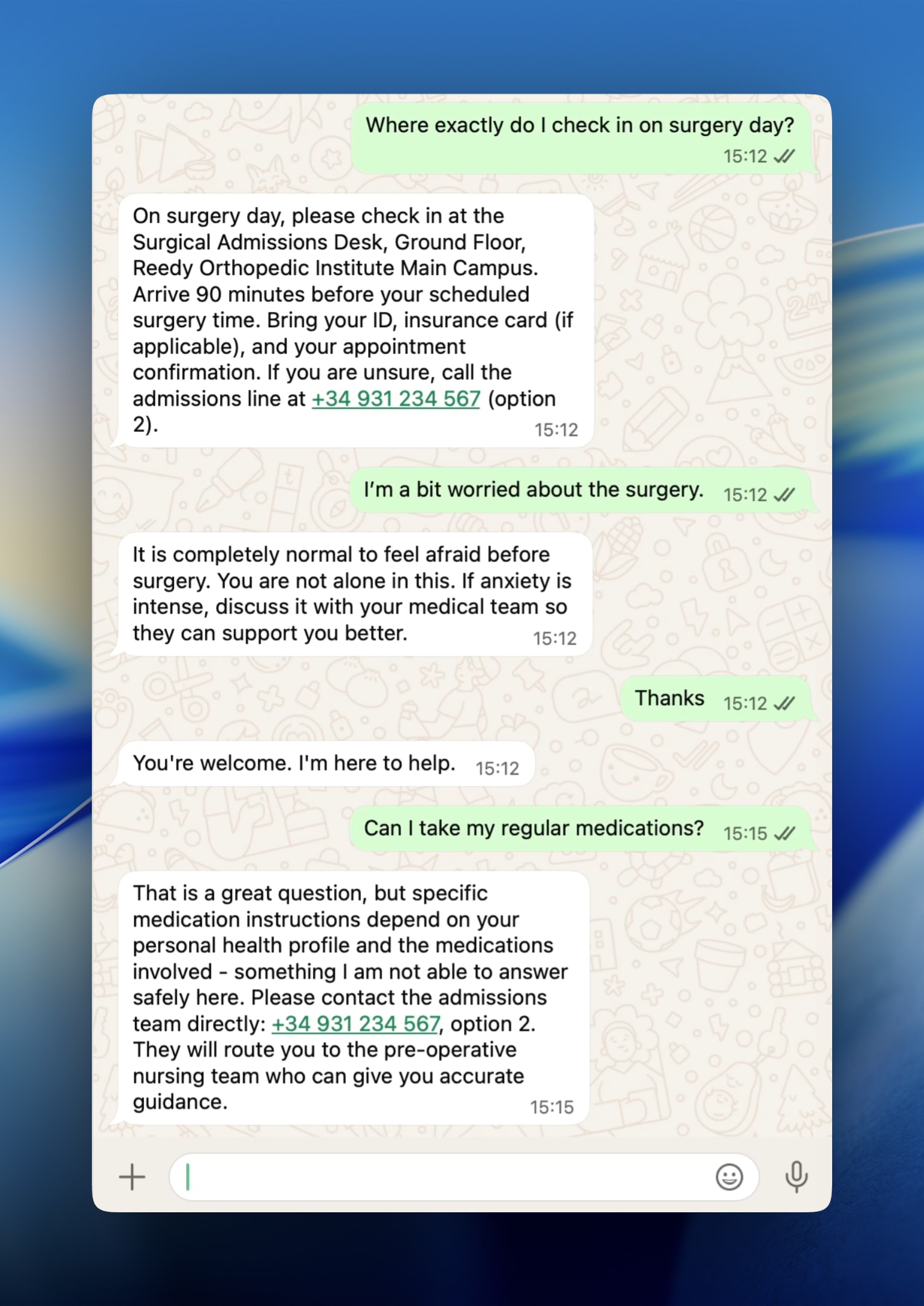
Paciente:
¿Puedo tomar mis medicamentos habituales?
Agente:
Buena pregunta, pero las instrucciones sobre medicación dependen de tu perfil de salud y de los fármacos concretos, y aquí no puedo responderte con seguridad. Contacta con admisiones: +34 931 234 567, opción 2; te pondrán con enfermería preoperatoria para una orientación precisa.
Un asistente que dice «no tengo esa información, llama aquí» es infinitamente más valioso que uno que adivina.
Arquitectura del sistema
El sistema tiene cuatro componentes principales: WhatsApp (usuario) → Twilio (webhook HTTPS) → servidor Node.js + Express (sesión + LLM) → respuesta vía API REST de Twilio de vuelta al usuario.
WhatsApp (usuario)
El usuario envía el mensaje.
Twilio Messaging API
HTTPS POST (webhook); reenvía a tu endpoint.
Servidor Node.js + Express
Almacén de sesiones (memoria / Redis), historial por usuario, recuperación desde una base de conocimiento preprocesada (RAG) y llamada al LLM con prompt de sistema más contexto recuperado.
WhatsApp (respuesta)
Twilio entrega el mensaje del asistente en el mismo hilo.
- Twilio
Cumplimiento de WhatsApp Business API, números y entrega. Tu servidor habla con Twilio, no con WhatsApp directamente.
- Node.js + Express
Recibe el webhook, extrae el mensaje, recupera el historial, busca fragmentos relevantes en una base de conocimiento preprocesada (RAG), llama al LLM y envía la respuesta con el cliente REST de Twilio.
- Almacén de sesiones
Historial por usuario. Un Map en memoria sirve para prototipo; en producción conviene Redis o almacén persistente con TTL.
- API del LLM
Prompt de sistema, restricciones y base de conocimiento; el historial viaja como array de mensajes en cada llamada.
Implementación: el código que importa
1. El prompt de sistema: la decisión de ingeniería más importante
El prompt define qué sabe el agente, cómo se comporta y qué se niega a hacer. Nota: en producción avanzada, la base de conocimiento no suele ir inline: se combina con RAG, APIs internas, versionado de conocimiento y contexto personalizado por usuario. Si quieres acelerar este tipo de implementaciones, Reedy ayuda a llevar sistemas de IA conversacional a producción con un stack RAG avanzado.
// prompts/systemPrompt.js
const SYSTEM_PROMPT = `
Eres un asistente prequirúrgico de pacientes para el Instituto Ortopédico Reedy.
Tu función es responder preguntas de pacientes en las 48 horas previas a cirugía electiva.
BASE DE CONOCIMIENTO:
- Protocolo de ayuno: no alimentos sólidos durante al menos 8 horas antes de cirugía.
Líquidos claros (agua, té solo, café negro) permitidos hasta 2 horas antes.
No chicles, caramelos duros, ni bebidas con leche después de medianoche.
- Ubicación de check-in: Mostrador de Admisiones Quirúrgicas, Planta Baja, Campus Principal.
Llegar 90 minutos antes de la hora programada de cirugía.
Documentos requeridos: DNI, tarjeta de seguro (si aplica), confirmación de cita.
Línea de admisiones: +34 931 234 567, opción 2.
- Respuestas emocionales comunes: la ansiedad antes de cirugía es normal y esperada.
Reconoce los sentimientos del paciente antes de proporcionar información.
Si la ansiedad se describe como severa o debilitante, recomienda discutirlo con el equipo médico.
REGLAS DE COMPORTAMIENTO:
1. Responde SOLO preguntas que puedas responder desde la base de conocimiento anterior.
2. Si una pregunta está fuera de alcance, dilo claramente y proporciona la línea de admisiones.
3. NUNCA inventes información médica específica que no esté presente en la base de conocimiento.
4. Mantén las respuestas concisas. Los pacientes leen esto en una pantalla de teléfono.
5. Si el paciente recibió instrucciones diferentes de su cirujano, SIEMPRE defiere al cirujano.
6. Saluda al paciente por su nombre en el primer mensaje si su nombre se conoce del contexto.
7. Responde en el mismo idioma que usa el paciente.
`;
module.exports = SYSTEM_PROMPT;
Decisiones de diseño críticas
La regla 2 es la válvula de seguridad: un agente fundamentado que deriva a humano vale más que uno que improvisa. En contextos clínicos no es negociable; en la mayoría de negocios es buena práctica.
La regla 7 permite entrada multilingüe sin lógica extra de enrutamiento: el modelo detecta el idioma y responde en consecuencia.
2. Gestión de sesiones: manteniendo el contexto
MAX_HISTORY_TURNS acota coste y ventana de contexto: las APIs cobran por token y un historial ilimitado es riesgo de facturación.
// sessions/sessionStore.js
const sessions = new Map();
const MAX_HISTORY_TURNS = 10; // keep last 10 exchanges to manage context window
function getHistory(userId) {
return sessions.get(userId) || [];
}
function addTurn(userId, role, content) {
const history = getHistory(userId);
history.push({ role, content });
// trim to max turns (each turn = 2 messages: user + assistant)
const maxMessages = MAX_HISTORY_TURNS * 2;
if (history.length > maxMessages) {
history.splice(0, history.length - maxMessages);
}
sessions.set(userId, history);
}
function clearHistory(userId) {
sessions.delete(userId);
}
module.exports = { getHistory, addTurn, clearHistory };
3. Cliente del LLM: la integración
max_tokens: 512 es intencional: en móvil, una respuesta que obliga a hacer scroll es mala UX.
// llm/claudeClient.js
const Anthropic = require('@anthropic-ai/sdk');
const SYSTEM_PROMPT = require('../prompts/systemPrompt');
const client = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY });
async function generateResponse(history, userMessage) {
// append the new user message to history before calling the API
const messages = [
...history,
{ role: 'user', content: userMessage }
];
const response = await client.messages.create({
model: 'claude-sonnet-4-20250514',
max_tokens: 512, // keep responses short for mobile reading
system: SYSTEM_PROMPT,
messages
});
return response.content[0].text;
}
module.exports = { generateResponse };
4. El servidor de webhooks: orquestación
Devuelve siempre 200 a Twilio, incluso en error, para evitar reintentos que dupliquen mensajes. El bloque catch debe enviar un fallback seguro hacia un humano. Usa req.body.From tal cual (incluye el prefijo whatsapp:) como clave de sesión y como destino de respuesta.
// server.js
require('dotenv').config();
const express = require('express');
const twilio = require('twilio');
const { getHistory, addTurn } = require('./sessions/sessionStore');
const { generateResponse } = require('./llm/claudeClient');
const app = express();
app.use(express.urlencoded({ extended: false }));
const twilioClient = twilio(
process.env.TWILIO_ACCOUNT_SID,
process.env.TWILIO_AUTH_TOKEN
);
app.post('/webhook', async (req, res) => {
// Twilio envía datos codificados en formulario
const incomingMessage = req.body.Body?.trim();
const fromNumber = req.body.From; // ej. "whatsapp:+34612345678"
if (!incomingMessage || !fromNumber) {
return res.status(400).send('Faltan campos requeridos');
}
try {
const history = getHistory(fromNumber);
const reply = await generateResponse(history, incomingMessage);
addTurn(fromNumber, 'user', incomingMessage);
addTurn(fromNumber, 'assistant', reply);
await twilioClient.messages.create({
from: process.env.TWILIO_WHATSAPP_NUMBER,
to: fromNumber,
body: reply
});
res.status(200).send('OK');
} catch (error) {
console.error('Error de webhook:', error);
await twilioClient.messages.create({
from: process.env.TWILIO_WHATSAPP_NUMBER,
to: fromNumber,
body: 'Estamos experimentando un problema temporal. Por favor, llama al +34 931 234 567 para asistencia inmediata.'
});
res.status(200).send('OK');
}
});
app.listen(process.env.PORT, () => {
console.log(`Servidor de webhook ejecutándose en puerto ${process.env.PORT}`);
});
De prototipo a producción: los 4 pilares
- 1. Validación de firma de webhook
Twilio firma cada petición (HMAC-SHA1). Valida con twilio.validateRequest(). Sin esto, quien descubra tu URL podría inyectar mensajes.
- 2. Almacén de sesiones persistente
Sustituye el Map por Redis, con TTL (p. ej. 24 h) para no acumular conversaciones obsoletas.
- 3. Rate limiting
Limita por número de teléfono (express-rate-limit + Redis) para evitar abuso y picos de coste en el LLM.
- 4. Logging estructurado y monitorización
Registra entradas, salidas y errores; evita almacenar el teléfono en claro si no es necesario (cumplimiento). Alerta sobre latencia y tasa de error.
Resultados observados en la implementación real
- 78% de cobertura
Ayuno, check-in y reconocimiento de ansiedad concentraron el 78% del tráfico: una base de conocimiento enfocada absorbe la mayor parte de la carga real.
- Latencia aceptable
Mediana ~2,1 s y p95 ~4,8 s entre webhook y entrega; razonable para mensajería asíncrona.
- 11% de derivación
Consultas enviadas a admisiones por estar fuera de alcance: por diseño, el agente no pretende cubrirlo todo.
- Satisfacción cualitativa
Los pacientes valoraron disponibilidad 24/7, especialmente fuera de horario cuando sube la ansiedad prequirúrgica.
Casos de uso en otras industrias
- Retail
Seguimiento de pedidos, stock, devoluciones.
- Inmobiliaria
Visitas, disponibilidad, preguntas sobre contratos.
- Servicios profesionales
Confirmación de citas, preparación de reuniones, FAQs.
- Educación y RR. HH.
Recordatorios, materiales, políticas internas o nóminas (siempre con grounding y escalado).
La pregunta correcta no es «¿WhatsApp puede hacer esto?», sino «¿tenemos un cuerpo de conocimiento del que un modelo bien instruido pueda extraer de forma fiable?». Si la respuesta es sí, el camino técnico suele ser más corto de lo que los equipos esperan.
Lecciones aprendidas y recomendaciones
Twilio + Node.js + un LLM actual forma un stack viable para producción en un abanico amplio de automatización conversacional.
Lo que determina si el asistente es útil o dañino es: (1) calidad del prompt de sistema, (2) disciplina de grounding, (3) robustez del camino de fallo hacia humanos.
La implementación mostrada ronda las 150 líneas de código; la complejidad operativa está en despliegue, gobierno del conocimiento y monitorización, no solo en la app.
Próximos pasos
1. ¿Qué preguntas repetitivas consumen tiempo de tu equipo?
2. ¿Tienes documentación o conocimiento estructurado que las responda?
3. ¿Hay un canal humano claro cuando la automatización no alcance?
Si las tres respuestas son sí, el camino técnico es más corto de lo que piensas.
Iniciemos tu proyecto
Te acompañamos con soluciones a medida, desde la idea hasta la implementación.