Análisis de Documentos con LLMs: De OCR a comprensión estructural.
Introducción
Extraer información útil desde documentos PDF y hojas de cálculo complejas ha sido, durante años, un gran desafío. Herramientas tradicionales como el OCR (Reconocimiento Óptico de Caracteres) fueron creadas para convertir texto en imágenes escaneadas a texto plano. Sin embargo, su enfoque es limitado: extraen los caracteres, pero pierden la estructura del documento, no comprenden jerarquías visuales ni relaciones contextuales entre columnas o celdas.
Por ejemplo, al procesar un estado financiero con un OCR o parser tradicional, algo como esta tabla de balance:

Puede ser mal interpretado como un listado lineal o secuencial de valores, rompiendo la relación entre cada título y su valor correspondiente. Esto ocurre porque el OCR no “ve” el layout de tabla, ni sabe que “ACTIVO NO CORRIENTE” con “40.000” y “Inmovilizado intangible” están en una misma columna estructurada, y mucho menos que hay dos bloques contables paralelos en el mismo renglón.
En la práctica, esto genera errores como:
Mezcla de columnas de activos y patrimonio neto.
Duplicación o pérdida de información.
Interpretaciones incorrectas al intentar convertir esto en datos utilizables.
Frente a estas limitaciones, los nuevos modelos de lenguaje grandes (LLMs) y modelos multimodales introducen el concepto de PDF understanding una forma de interpretar no solo el texto, sino también la estructura visual y semántica del documento. Herramientas como LlamaParse utilizan estos modelos para mantener relaciones de columnas, jerarquía visual (títulos, subtítulos, agrupaciones) y contexto, incluso en documentos con estructuras mixtas como tablas contables o balances financieros.
Por ejemplo, en el mismo caso anterior, LlamaParse puede identificar correctamente que hay dos secciones (Activos vs Patrimonio Neto), con sus respectivos subtítulos e importes, preservando su distribución original y convirtiéndolo en una tabla estructurada válida para consulta o análisis.
Este salto tecnológico marca una transición clara: del OCR que simplemente “lee letras”, al LLM que comprende el documento como un todo.
LlamaParse y LlamaCloud
El auge de los modelos de lenguaje ha generado una nueva categoría de herramientas especializadas en transformar documentos no estructurados en datos comprensibles para la inteligencia artificial. En este contexto, LlamaParse se posiciona como una de las soluciones más robustas y versátiles para interpretar PDFs y otros formatos complejos. Su integración en la plataforma LlamaCloud permite escalar estos procesos a nivel empresarial.
LlamaParse és un motor de parsing desenvolupat per LlamaIndex, dissenyat específicament per integrar-se amb models generatius i fluxos de RAG (Retrieval-Augmented Generation).
A diferència dels parsers tradicionals, LlamaParse està optimitzat per extreure text, taules, jerarquia estructural i contingut visual com imatges o diagrames, tot en un format fàcilment digerible pels LLMs.
Soporta múltiples tipos de archivo, entre ellos:
DOCX, PPTX, XLSX
EPUB, HTML, JPEG
Archivos ZIP con múltiples documentos
Además, ofrece salida en Markdown enriquecido y JSON estructurado, y puede integrarse con herramientas como LlamaIndex, LangChain o cualquier LLM vía API.
Ejemplo
Supongamos que subes un contrato en PDF con títulos como “Cláusula 1: Objeto del contrato” y “Cláusula 2: Obligaciones del proveedor”. Un parser normal puede devolver texto plano, sin distinguir secciones. LlamaParse, en cambio, te devolverá una estructura jerárquica como esta:
¿Qué es LlamaCloud?
Infraestructura en la nube donde vive LlamaParse, diseñada para ofrecer:
Procesamiento escalable y asincrónico.
Procesamiento por lotes.
Gestión de documentos y resultados parseados.
Interfaz API y SDKs (CLI, Python).
Compatibilidad con herramientas como Neo4j, Snowflake, LangChain y más.
Además, LlamaCloud permite configurar procesamiento personalizado: desde formatos de salida hasta puntuaciones de confianza por página, corrección de inclinación, detección de idioma y mucho más.
Ejemplo práctico
Un caso real muy común es el procesamiento de manuales técnicos PDF con muchas tablas, encabezados y diagramas. LlamaParse no solo extrae el contenido textual, sino que preserva el diseño de tablas (incluso con celdas combinadas), extrae las imágenes como archivos separados, y mantiene los encabezados jerarquizados.
Por ejemplo, un diagrama dentro del documento será devuelto como:
{
"type": "image",
"description": "Diagrama de flujo del proceso",
"path": "doc_assets/image_2.png"
}
Y una tabla de especificaciones técnicas podrá convertirse en Markdown o JSON estructurado listo para alimentar un motor de búsqueda, agente LLM o base de datos.
La combinación de LlamaParse + LlamaCloud permite transformar documentos complejos en representaciones fieles y estructuradas, preparadas para tareas como búsqueda semántica, RAG, extracción de datos o generación de resúmenes inteligentes. Su diseño nativo para LLMs marca la diferencia frente a parsers tradicionales que no comprenden el contexto ni la intención del documento.
Ventajas clave y ejemplos de uso
LlamaParse no es solo un parser “más moderno”, sino una herramienta que redefine cómo extraemos y usamos la información contenida en documentos complejos. A continuación, repasamos sus beneficios clave frente a enfoques tradicionales, y mostramos cómo empresas reales ya están aprovechando su potencia en distintos sectores.
Ventajas principales
- Preservación de estructura y jerarquía
A diferencia de parsers tradicionales que devuelven texto plano, LlamaParse conserva la jerarquía visual y lógica del documento: títulos, subtítulos, listas, tablas, pies de imagen y más.
Ejemplo: En un manual técnico, los encabezados como1. Introducción,1.1 Alcancey1.2 Limitacionesson convertidos en Markdown con indentación apropiada, permitiendo búsquedas contextuales o navegación con LLMs. - Manejo avanzado de tablas
LlamaParse interpreta correctamente tablas con múltiples capas de encabezados, celdas fusionadas, subtotales y formatos mixtos (números, fechas, texto).
Ejemplo: En un balance financiero como el que compartiste, LlamaParse puede identificar que “A) Activo no corriente” y “A) Patrimonio neto” pertenecen a columnas distintas, y que “0,00” está correctamente alineado con su categoría contable, sin mezclar datos. - Extracción multimodal (texto + imágenes)
Extrae imágenes, diagramas y gráficos del documento, generando metadatos útiles como descripción, posición y relación con el texto.
Ejemplo: En una presentación en PDF, cada diagrama puede ser almacenado como archivo `.png` vinculado a su pie de figura, permitiendo su uso separado o interpretación por un modelo de visión. - Listo para LLMs
La salida (en Markdown, JSON o XML) está optimizada para alimentar modelos generativos, motores de RAG, embeddings, agentes o workflows de extracción automatizada.
Ejemplo: Una cláusula legal extraída por LlamaParse puede usarse directamente en una pregunta a un LLM: “¿En qué cláusula del contrato se menciona el período de cancelación?”, y la respuesta incluirá un fragmento preciso, con referencia a la sección correcta.
Casos de uso por sector
- Finanzas y contabilidad
Parsing de balances, informes anuales y facturas. Extracción de KPIs y comparación de métricas entre documentos.
- Legal y compliance
Ingesta masiva de contratos con extracción de cláusulas clave (fechas, obligaciones, penalizaciones). Creación de buscadores semánticos para revisión de documentos legales.
- Recursos Humanos
Extracción de datos desde CVs, formularios de evaluación, hojas de vida. Generación de resúmenes de candidatos o detección de requisitos clave.
- I+D y documentación técnica
Procesamiento de papers, manuales, patentes y reportes científicos. Construcción de grafos de conocimiento o búsqueda por contenido técnico.
Errores comunes y estrategias de implementación
Aunque LlamaParse facilita enormemente la extracción de información de documentos, su implementación no está exenta de retos. Muchas organizaciones, al integrar este tipo de soluciones, tropiezan con errores comunes que pueden afectar la calidad de los resultados o la eficiencia del flujo de trabajo. A continuación, revisamos los más frecuentes y las mejores prácticas para evitarlos.
Errores comunes
- Subestimar la complejidad del dataset
Algunas empresas intentan procesar todo su repositorio documental de una sola vez sin auditar previamente el tipo de documentos. Esto suele provocar inconsistencias en los resultados.
Ejemplo: Una aseguradora carga formularios, contratos y reportes médicos en el mismo lote, esperando una salida homogénea. El resultado es mezcla de formatos y pérdida de precisión en ciertos tipos de documentos. - Ignorar el layout y la jerarquía
Aunque LlamaParse preserva estructura, si no se configura la salida adecuada (Markdown vs JSON, por ejemplo), se corre el riesgo de obtener resultados difíciles de explotar.
Ejemplo: Un balance financiero extraído en texto plano pierde las relaciones entre columnas, mientras que configurado en JSON preserva cada bloque con su etiqueta contable correcta. - No establecer validaciones de calidad
Al confiar ciegamente en el parser, se corre el riesgo de usar datos incorrectos. LlamaParse ofrece puntuaciones de confianza por página, pero muchas veces no se utilizan.
Ejemplo: Un documento escaneado con baja calidad es procesado sin revisión. Luego, un LLM da respuestas basadas en datos incompletos, afectando la toma de decisiones. - Procesar en lotes sin control de errores
Cuando se suben cientos de documentos en paralelo, un fallo en uno puede detener todo el proceso si no se aplican buenas prácticas de resiliencia.
Ejemplo: En una auditoría legal, si un solo contrato genera error, el sistema pausa la ejecución completa en lugar de procesar los demás.
Estrategias recomendadas
- Fase de auditoría inicial
Identificar qué documentos aportan mayor valor al parseo y cuáles son más complejos (ej. balances, contratos, manuales técnicos). Esto permite priorizar y optimizar.
- Pilotos controlados
Empezar con un conjunto pequeño de documentos para probar configuraciones (Markdown, JSON, XML) y validar que la salida sea útil para el caso de uso.
- Uso de puntuaciones de confianza
Configurar alertas o revisiones humanas en páginas con baja puntuación, reduciendo errores críticos en datos sensibles.
- Procesamiento por lotes con recuperación
Usar la infraestructura de LlamaCloud para procesar documentos en paralelo, con checkpointing y reintentos automáticos en caso de fallos.
- Ciclos de retroalimentación
Integrar revisiones manuales y feedback loops para mejorar continuamente el parsing y adaptar configuraciones según los documentos más frecuentes.
Ejemplo práctico 1: Parsing de datos financieros en PDF y Excel
Uno de los escenarios más comunes donde las soluciones tradicionales de OCR fallan es en la extracción de información financiera desde documentos PDF escaneados o tablas contables en Excel. En este tipo de archivos, la estructura tabular es crítica: no basta con leer los números, sino que es necesario mantener la relación entre cada concepto y su importe correspondiente.
El reto con OCR tradicional
- Pérdida de datos
Algunos importes no fueron detectados, en especial cuando estaban alineados a la derecha.
- Errores de caracteres
Se introdujeron cifras inexistentes (ej. leer “80.000” como “80000l”).
- Saltos de línea incorrectos
Filas de tablas partidas en dos, lo que rompía la coherencia entre el título y su valor.
- Desalineación de columnas
Conceptos del “Activo” mezclados con importes del “Pasivo”.
Ejemplo con OCR (Tesseract)
El resultado es un texto plano, lleno de errores y sin una estructura confiable.
Parsing con LlamaParse
En contraste, al procesar el mismo documento con LlamaParse, se obtuvieron resultados estructurados y jerárquicos, preservando el formato tabular y eliminando los errores de OCR.
Ejemplo con LlamaParse (salida en Markdown):
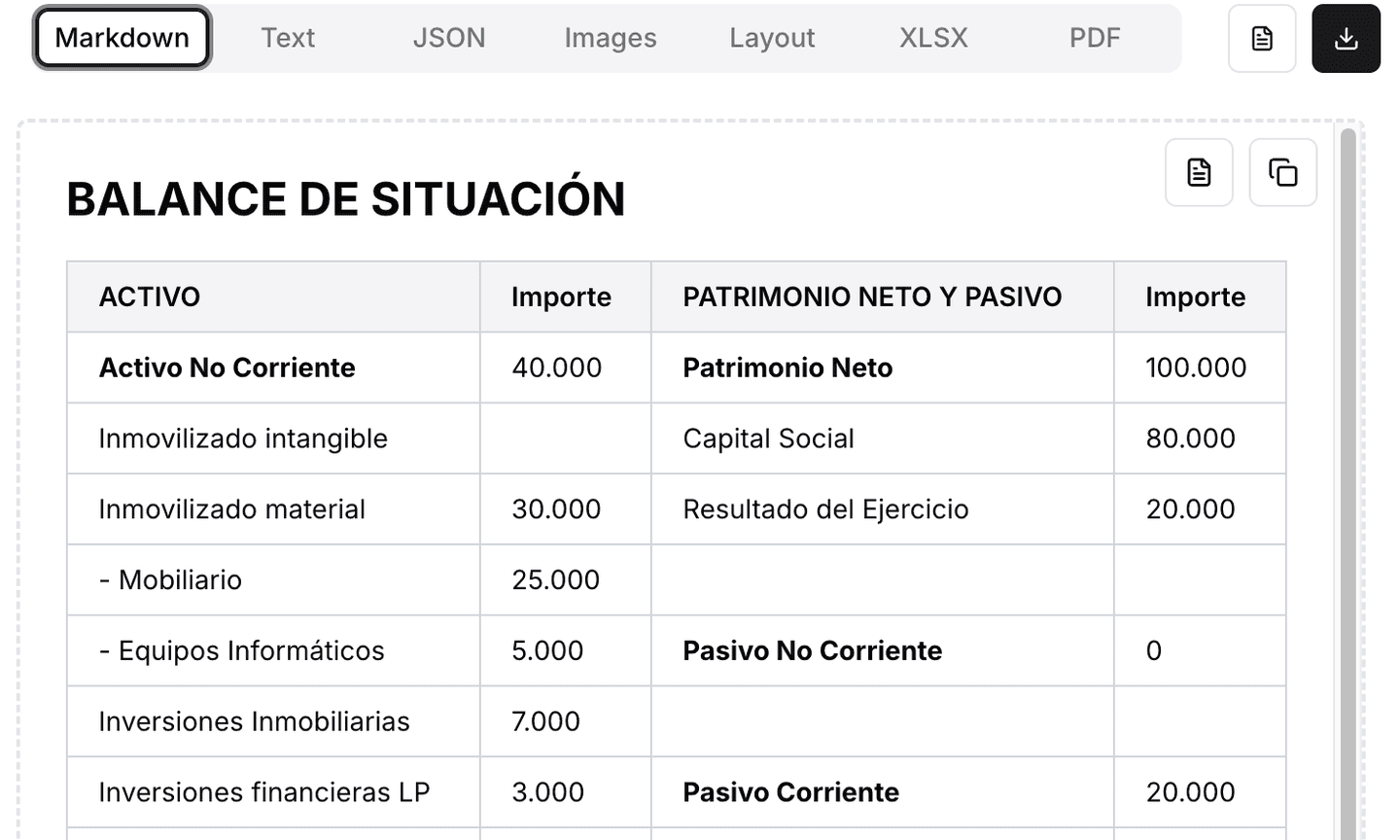
Beneficios observados
Preservación de la jerarquía: se diferencian claramente secciones, subtotales y conceptos.
Tablas interpretadas correctamente: se mantuvo la relación entre columnas de “Activo” y “Pasivo”.
Cero errores de caracteres: los importes se extrajeron fielmente.
Formato usable directamente: la salida en Markdown o JSON puede conectarse a un motor de búsqueda, un dashboard financiero o una base de datos.
Conclusión del caso
Mientras que el OCR tradicional genera un texto plano ruidoso y difícil de explotar, LlamaParse devuelve una estructura fiel al documento original, lista para ser utilizada en flujos de análisis financiero, auditoría o consulta con LLMs.
Ejemplo práctico 2: Manual de reparación (texto + imágenes + diagramas)
En manuales técnicos escaneados es común que el OCR “despegue” el texto de sus figuras: las fotos quedan sin pie, los pasos se mezclan y los diagramas se pierden. En nuestro caso, el mayor problema fue asociar cada imagen de la reparación con su descripción.
Con LlamaParse, resolvimos dos cosas a la vez:
Extracción de imágenes como archivos individuales (p. ej., `page_03_fig_02.png`).
Generación de descripciones/alt-text y vinculación de cada imagen con su paso y pie de figura.
Qué falla con OCR tradicional (antes)
Imágenes no extraídas o sin nombres útiles.
Pies de figura (“Fig. 2 – Retirar tapa trasera”) quedan como texto suelto.
Pérdida del orden: el “Paso 3” puede terminar lejos de su foto.
Salida típica (OCR):
Qué devuelve LlamaParse (después)
LlamaParse mantiene el contexto visual y el orden, y además puede crear una representación estructurada (JSON/Markdown) donde cada paso referencia explícitamente su imagen.
Ejemplo de salida (JSON) simplificado:
{
"document_title": "Manual de reparación - Lavadora X200",
"sections": [
{
"title": "Desmontaje",
"steps": [
{
"step_number": 3,
"text": "Retire la tapa trasera retirando 4 tornillos Phillips.",
"figure_ref": "Fig. 2",
"image": {
"path": "assets/page_03_fig_02.png",
"alt": "Vista posterior de la lavadora con tapa trasera y ubicación de 4 tornillos Phillips",
"page": 3,
"bbox": [128, 244, 612, 531]
}
},
{
"step_number": 4,
"text": "Desconecte la manguera de desagüe del conjunto de la bomba.",
"figure_ref": "Fig. 3",
"image": {
"path": "assets/page_04_fig_03.png",
"alt": "Detalle de la manguera de desagüe conectada a la bomba de agua",
"page": 4,
"bbox": [96, 210, 580, 500]
},
"warnings": [
"Asegúrese de cerrar la válvula de agua antes de desconectar la manguera."
]
}
]
}
]
}
Qué aporta esto:
step_number y figure_ref aseguran la relación paso–figura.
image.path te entrega el archivo recortado listo para UI o informes.
alt es la descripción generada (útil para accesibilidad y búsqueda).
page y bbox (posición) permiten grounding y validaciones visuales.
Variante en Markdown (lista de pasos con imágenes)
Flujo recomendado (resumen)
Sube el PDF escaneado del manual a LlamaParse.
Configura salida JSON (para estructura) o Markdown (para docs/UI).
Habilita extracción de imágenes y descripciones (alt-text).
Usa los campos page/bbox para validar visualmente o construir previews.
Integra el JSON en tu app: renderiza cada paso con su imagen y advertencias.
Beneficios observados
Asociación paso–imagen confiable (se evita el “despegue” típico del OCR).
Accesibilidad y buscabilidad gracias al alt-text generado.
Trazabilidad total: puedes volver a la página exacta y región donde aparece la imagen.
Listo para RAG: “Muéstrame el paso donde se retira la tapa trasera y su foto”.
De la extracción al RAG: almacenamiento, embeddings y chunking jerárquico
Una vez procesado el documento con LlamaParse, no solo contamos con el texto extraído, sino también con una representación rica en estructura, imágenes y metadatos. Este material es la base para construir pipelines de Retrieval-Augmented Generation (RAG), ya que permite organizar la información en unidades consultables y optimizar tanto la recuperación como la generación.
Qué tenemos tras LlamaParse
Texto estructurado (Markdown/JSON) con secciones, tablas y pasos.
Imágenes extraídas (archivos) + descripciones/alt-text + (opcional) posición (page, bbox).
Metadatos (título, encabezados H1/H2…, figure_ref, tipos de bloque, etc.).
Esquema de almacenamiento recomendado
{
"doc_id": "manual_x200_v1",
"title": "Manual de reparación - Lavadora X200",
"source": "s3://bucket/manuales/x200.pdf",
"created_at": "2025-08-28",
"doctype": "manual|balance|contrato"
}
{
"chunk_id": "manual_x200_v1#sec1#step3",
"doc_id": "manual_x200_v1",
"hierarchy": ["Desmontaje", "Paso 3"],
"text": "Retire la tapa trasera retirando 4 tornillos ...",
"tables": [],
"images": [
{
"path": "assets/page_03_fig_02.png",
"alt": "Vista posterior de la lavadora...",
"page": 3,
"bbox": [128,244,612,531]
}
],
"metadata": {
"page": 3,
"figure_ref": "Fig. 2",
"block_type": "step",
"layout": "single-column"
}
}
c) Typical Storage Layers
Text/JSON: document databases (MongoDB) or object storage (S3/GCS) with SQL indexing.
Images: object storage (S3/GCS/Azure Blob), storing only the path in the chunks.
Vectors: vector DB (FAISS/pgvector/Pinecone/Weaviate/Qdrant). Store:
- embedding_text (mandatory)
- embedding_table (optional, for serialized tables)
- embedding_image (optional, for multimodal RAG)
- metadata (doc_id, page, headers, figure_ref, block type, etc.)
How to Vectorize? (Text, Tables, Images)
Text: Sentence/paragraph embeddings. Ideal chunk size: 300–800 tokens with 10–20% overlap. Include hierarchical context in the vectorized text: “[Manual X200 > Disassembly > Step 3] Remove the back cover…”.
Tables: Avoid arbitrary flattening. Serialize by row or logical block (faithful CSV/Markdown + title + notes), or create a schema+values summary embedding.
Images:
1) Text-first (simple): use LlamaParse alt-text, vectorize it, store the image path.
2) Multimodal (advanced): create image embeddings (CLIP/LLM-vision) and store an image vector along with alt-text.
Hierarchical Chunking (Critical for Good Answers)
Respect structure: a chunk should never mix unrelated sections.
Semantic units: Manual → each step + its figure(s). Balance sheet → accounting blocks (use sub-chunks if long).
Include hierarchical context (breadcrumb path) inside each chunk.
Never split tables mid-row (avoid partial rows).
Moderate overlap (10–20%) to preserve continuity without redundancy.
Recommended Query Flow (RAG)
Hybrid retrieval: keyword + vector (BM25/SQL + embeddings).
Reranking: pass top-k candidates to a reranker (optional).
Hierarchical context builder: merge sibling/parent chunks when the prompt requires; for tables, include headers and notes.
Grounded answers with citations: return text + image paths (and page/bbox if needed). For balance sheets, preserve units and numeric formatting (thousand separators, decimals).
Mini-snippets (orientativos)
from sentence_transformers import SentenceTransformer
import faiss, numpy as np
model = SentenceTransformer("all-MiniLM-L6-v2")
docs = [
{
"chunk_id": "manual_x200_v1#sec1#step3",
"text": "[Manual X200 > Desmontaje > Paso 3] Retire la tapa trasera...",
"image_alt": "Vista posterior de la lavadora..."
},
{
"chunk_id": "balance_2024#activo_corriente#existencias",
"text": "[Balance 2024 > Activo Corriente > Existencias] Mercaderías: 40.000",
"image_alt": None
}
]
texts = [d["text"] for d in docs] + [d["image_alt"] for d in docs if d["image_alt"]]
emb = model.encode(texts, normalize_embeddings=True)
index = faiss.IndexFlatIP(emb.shape[1])
index.add(np.array(emb, dtype="float32"))
Esquema de metadatos (guardar junto a cada vector)
{
"chunk_id": "manual_x200_v1#sec1#step3",
"doc_id": "manual_x200_v1",
"headers": ["Desmontaje", "Paso 3"],
"image_paths": ["assets/page_03_fig_02.png"],
"page": 3,
"figure_ref": "Fig. 2",
"block_type": "step"
}
La extracción “ciega” de texto dejó de ser suficiente. A lo largo del artículo vimos cómo el PDF understanding basado en LLMs y, en particular, LlamaParse sobre LlamaCloud, transforma documentos complejos en datos estructurados y confiables: respeta el layout, entiende la jerarquía y relaciona correctamente tablas, figuras y texto.
En finanzas (balances): preservó relaciones entre columnas y subtotales, evitando errores de OCR.
En manuales técnicos: resolvió el vínculo paso↔figura con extracción de imágenes y descripciones.
Después de extraer, el valor se consolida con una canalización de RAG bien diseñada
Almacenamiento de texto/JSON, tablas e imágenes con metadatos.
Embeddings de texto (y opcionales de tablas/imágenes).
Chunking jerárquico con contexto y solape moderado.
Construcción de contexto con grounding (página/bbox) y devolución de citas e imágenes.
Lecciones clave
El layout importa: no aplanes tablas ni mezcles bloques heterogéneos.
La jerarquía manda: los chunks deben reflejar la estructura del documento.
La multimodalidad suma: alt-text + imagen mejora accesibilidad y búsqueda.
La calidad se gobierna: puntuaciones de confianza, revisiones humanas y monitoreo.
En síntesis, pasar de OCR a LLMs no es solo mejorar la lectura: es habilitar respuestas precisas, citables y accionables sobre documentos antes opacos. Con LlamaParse + buenas prácticas de RAG, cualquier organización puede convertir sus PDFs en una fuente viva de conocimiento.
Iniciemos tu proyecto
Te acompañamos con soluciones a medida, desde la idea hasta la implementación.