Agentic SOPs: Turning SOPs into Decision Graphs and Reliable Agents.
How Decision Graphs Make LLMs Reliable.
Large language models are good at writing and reasoning in the small, but they’re brittle the moment a task becomes a policy-heavy, multi-step workflow: plans drift, tools get called out of order, and a single hallucination can derail the run. The SOP-Agent paper proposes a pragmatic fix: encode your organization’s Standard Operating Procedures (SOPs) in natural language, compile them into a decision graph (nodes = actions, edges = IF/ALWAYS conditions), and let an agent selectively traverse that graph while only seeing a filtered set of valid tools at each step. In other words, you keep human policy in charge, the agent supplies the judgment and calling.
Concretely, SOP-Agent has two moving parts: a SOP-Navigator sthat formats the current slice of the SOP and limits the action space, and a Base Agent (often an LLM) that proposes the next function call (and arguments). The traversal is DFS-style (Depth-first Search) so the system can go deep when a branch’s preconditions are satisfied, and it includes a neat trick for ambiguous forks—when two children share the same function or have no function at all, the agent first calls a dummy “explore_subtree_X” tool to commit to a branch, then generates the real action inside that subtree. This keeps the number of LLM calls low while preserving control.
Why should you care? Because the results suggest SOP-grounding trades “clever but flaky” for “smart and reliable” across very different tasks. In the ALFWorld decision-making benchmark, a SOP-guided agent reaches 0.888 success (few-shot), surpassing a strong ReAct baseline and far outpacing AutoGPT variants. In a practical data-cleaning setup, it achieves a 100% success rate, competitive with a domain-specialized system. And in a new Grounded Customer Service benchmark (five industries, SOP-driven flows), the approach posts ~99.8% accuracy while remaining auditable and policy-compliant—exactly what ops teams want.
This article draws on the paper “SOP-Agent: Empower General Purpose AI Agent with Domain-Specific SOPs” (Ye et al.), released on arXiv in 2025 (arXiv:2501.09316). The authors formalize SOPs as decision graphs, introduce the SOP-Navigator + Base Agent architecture (including the dummy explore_subtree_* pattern for ambiguous branches), and report strong results across ALFWorld, code generation (HumanEval/MBPP), data cleaning, and a new Grounded Customer Service benchmark.
2- The SOP-Agent idea
Core move: write your SOP in natural language (bullets or pseudocode), compile it into a decision graph, and execute that graph with guardrails. The graph has:
Nodes = actions your system can take (e.g., get_order_status, cancel_order, open_ticket).
Edges = conditions that decide where to go next (simple IF/ALWAYS checks on facts in state).
A shared blackboard (state) that accumulates facts from tool calls (e.g., {"status": "shipped", "cancelled": true}).
At runtime, an agent loop does: Act → Observe → Route → Repeat it:
Call the node’s tool (Act).
Merge its output into the blackboard (Observe).
Evaluate edge conditions to pick the next node (Route).
Continue until a terminal node.
Two components carry this out:
SOP-Navigator (scaffold): keeps the current node + blackboard, formats a compact view of “what’s allowed next,” and filters the tool list to only the valid next actions for this step.
Base Agent (decider): usually an LLM that, within those filtered tools, chooses which tool to call and with what arguments when judgment helps. (You can also run without an LLM—purely deterministic.)
Why this works
Guardrails: the SOP graph dictates order, legality, and exit conditions; unknown tools are simply not visible.
Judgment where it matters: when several branches are plausible or arguments must be synthesized, the agent (LLM) chooses—but still inside the SOP fence.
Efficient traversal: the system tends to go depth-first (commit to a branch, run its steps) instead of flitting around, which reduces wasted calls and planning drift.
Ambiguous forks handled cleanly: if two children share the same function (or have no function), the navigator offers dummy “explore_subtree_X” tools so the agent picks a branch first; the real action happens one hop deeper.
A tiny example SOP (human-readable → graph)
id: order_flow
root: authenticate
nodes:
authenticate:
action: auth_and_fetch(order_id)
edges:
- condition: ALWAYS
to: check_status
check_status:
action: get_order_status(order_id)
edges:
- condition: status == "shipped"
to: offer_return
- condition: status in ["processing","packed"]
to: cancel_with_fee
- condition: status == "error"
to: escalate
offer_return:
action: propose_return(order_id)
edges:
- condition: ALWAYS
to: end
cancel_with_fee:
action: cancel_order(order_id)
edges:
- condition: ALWAYS
to: notify_fee
notify_fee:
action: send_fee_notice(order_id)
edges:
- condition: ALWAYS
to: end
escalate:
action: open_ticket(order_id)
edges:
- condition: ALWAYS
to: end
end:
terminal: true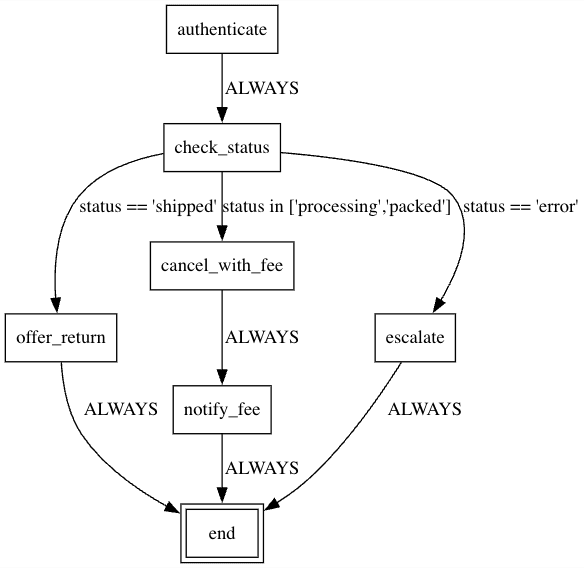
What happens at one step (e.g., check_status)
Tool runs: get_order_status(order_id) → returns {"status": "packed"}
Blackboard updates: now includes status: "packed"
Navigator filters tools: next valid children imply actions {propose_return, cancel_order, open_ticket}
Agent decides (optional): LLM picks cancel_order and proposes {"order_id": "A3"}
Route via SOP edges: status in ["processing","packed"] is true → go to cancel_with_fee.
What’s “agentic” vs “deterministic” here?
Deterministic mode (no LLM): you still execute the SOP graph reliably—great for audits and repeatability.
Agentic mode (with LLM decider): at nodes with ambiguity or parameter needs, the model chooses among only the allowed tools and fills arguments; the SOP still governs transitions. You get adaptability without giving up policy.
Key properties you’ll rely on later
Filtered tools per node (reduces hallucination).
Simple, safe condition DSL for edges (==, !=, <, >, in, and/or/not, plus ALWAYS).
Selective DFS traversal (commit, go deep, then move on).
Dummy “explore” actions for ambiguous branches (keeps prompts short and decisions crisp).
3- Implementation A ,Deterministic engine (no LLM)
Loads a human-readable SOP (YAML).
Compiles it into a decision graph (nodes, edges).
Runs the graph in a tight loop: Act → Observe → Route → Repeat—no model involved, so runs are deterministic and fully auditable.

Two components carry this out:
action: the tool to call (a Python function or API wrapper).
args: the named parameters that tool expects (often taken from the blackboard).
edges: list of { condition, to } telling the engine where to go next.
terminal: true for the final node.
Edges are evaluated in order; the first true condition wins. If none match, the engine raises an error (great for catching holes in the SOP).
Why this works
Boolean: and, or, not
args: the named parameters that tool expects (often taken from the blackboard).
Comparison: ==, !=, <, <=, >, >=
Membership: in, not in
Shortcut: ALWAYS (always true)
Names in conditions (e.g., status) are looked up on the blackboard—the shared dict of facts accumulated from tool outputs. This keeps control flow transparent and testable.
3.4 Runner loop (how execution works) Pseudocode:
bb = {order_id: ...} # blackboard starts with inputs
node = root
while not node.terminal:
# Act
obs = call(node.action, args from bb)
# Observe
bb.update(obs)
# Route (first matching edge)
node = first child where eval(condition, bb) == True
# doneDesign choices that help in prod:
Tool allow-list: only actions present in the SOP can be called.
Time-outs / retries at the tool layer (idempotent where possible).
Structured logging: (node, action, args, obs, chosen edge) per step.
All runs begin with:
authenticate → sets auth:"ok", customer_id, carries order_id → ALWAYS → check_status
check_status → sets status ("shipped", "processing", "packed", or "error")
Then the SOP routes:
A1 (shipped): status == "shipped" → offer_return (propose return) → end Final state includes return_offered: true.
A2 (processing) and A3 (packed): status in ["processing", "packed"] → cancel_with_fee → notify_fee → end Final state includes cancelled: true, fee: 5.0, notice_sent: true.
A4 (error): status == "error" → escalate (open ticket) → end Final state includes ticket_opened: true.
You get a Path (the exact node sequence)< and a Blackboard (all facts gathered). That’s your audit trail.
Determinism & compliance: the SOP is the source of truth; no surprises.
Auditability: every step, input, and observation is recorded.
No judgment: when branches are fuzzy or parameters must be synthesized from messy text, the deterministic engine can’t improvise—that’s where the LLM-assisted variant helps (next section).
4- Implementation B ,LLM-decider variant (agentic, SOP-guarded)
4.1 Why add an LLM if we already have rules? Rules (the SOP graph) are great at order, policy, and termination. Real life adds judgment:
Multiple branches are plausible given the same facts (e.g., refund vs. reship).
Tools need arguments derived from messy inputs (tone, complaint text, screenshots).
Some facts aren’t available yet; we must decide what to ask for next.
The agentic engine adds an LLM decider (often a general-purpose LLM) to handle:The LLM steps in as a decider at those moments—but only inside the guardrails the SOP exposes.
4.2 The “chooser” contract (JSON-only, whitelisted tools) At a node with multiple valid children, the Navigator builds a filtered list of allowed tools for the next step. The LLM receives:
A short context: current node description + the blackboard (facts).
The allow-list of tools for this step (e.g., ["propose_return","cancel_order","open_ticket"]).
A strict instruction to return only JSON:
{"name": "", "args": { /* minimal, valid args */ }}
We then validate:
`"name"`∈ allowed tools
`"args"` is an object (and optionally schema-checked per tool)
If invalid, we retry with a brief corrective message. This keeps the LLM’s output predictable and auditable.
4.3 Prompt design: short, factual, and grounded in state A good chooser prompt is:
Compact: node summary + blackboard facts only.
Constrained: explicitly lists the allowed tools.
Actionable: requests a single JSON object (name, args).
Example (conceptual):
You are at SOP node 'check_status': Inspect the order status.
Observations: {"order_id":"A3","status":"packed","auth":"ok"}
Allowed tools: propose_return, cancel_order, open_ticket
Return ONLY: {"name":"","args":{...}}
4.4 Guardrails that preserve control Even with an LLM decider, the SOP stays in charge:
Tool allow-list (per node) ,the agent cannot see or call anything else.
Structured output ,we accept only `{"name":..., "args":{...}}`, no free-text.
Post-choice routing ,after executing the chosen tool, we still evaluate SOP edge conditions to pick the next node. If the tool didn’t make a branch valid, the route won’t change.
Argument checking ,optional per-tool schema (types, required keys, ranges).
Observability ,log (prompt, allowed tools, model output, chosen action, args, tool result, next node).
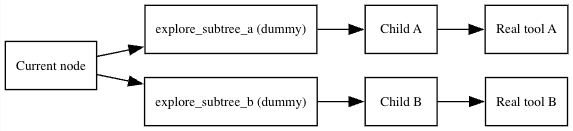
4.5 Handling ambiguous forks with “dummy explore” tools Sometimes children are ambiguous:
Several children share the same next tool, or
Some children have no tool at their entry node.
To keep decisions crisp, the Navigator replaces the real tools with dummy selectors
Allowed tools: explore_subtree_a, explore_subtree_b, explore_subtree_c
The LLM picks a subtree (fast, low-cognitive-load). We then route to that child and ask for a real tool one hop deeper where actions diverge. This mirrors the paper’s trick to minimize unnecessary model calls while keeping traversal depth-first and decisive.
4.7 E-commerce walkthrough (with LLM in the loop) Using the same SOP as before:
A1 (status = "shipped") Allowed tools for the next hop imply a return path. The LLM chooses `{"name":"propose_return","args":{"order_id":"A1"}}`. We execute it; the condition `status == "shipped"` remains true, and the SOP routes to `offer_return → end`.
A2 / A3 ("processing" / "packed") The LLM typically selects `cancel_order` with the correct `order_id`. After execution, routing follows `cancel_with_fee → notify_fee → end`.
A4 ("error") The LLM selects `open_ticket`; the SOP routes to `escalate → end`.
If we manufactured an ambiguous node (e.g., two children with no entry action), the Navigator would first present `explore_subtree_*` options; the LLM commits to a subtree, then we ask for the concrete tool inside it.
4.8 Failure modes & mitigations
Model proposes a non-allowed tool → hard reject + retry with a short corrective message.
Arguments missing or malformed → schema validate; request a corrected JSON.
No edge becomes true after the tool → fall back to the SOP’s next best edge order or raise a clear error (great for SOP refinement).
Hallucinated decisions → tighten prompts, keep the allow-list small, and add **postconditions** (e.g., ensure `status` exists before routing further).
4.9 What you gain (compared to deterministic)
Judgment on demand the model picks between plausible paths and synthesizes arguments.
Still controlled the SOP graph defines legality and order; routing is rule-based.
Better fit for unstructured inputs free-text complaints → structured args.
5-SOP engineering & testing
5.1 Best practices for conditions (the mini-DSL)
Anchor conditions to specific observations. Prefer `status == "shipped"` where `status` is produced by `get_order_status`, not vague checks like `if ready`.
Avoid overlapping branches. If two edges can both be true, order decides—so either make them mutually exclusive or place a **clear priority order** and comment it.
Always include a catch-all. Add a final `ALWAYS` → `escalate` (or similar) to avoid dead ends when the world surprises you.
Prefer positive checks over negations. `status in ["processing","packed"]` is easier to reason about than `not (status == "shipped" or status == "error")`.
Keep conditions small and typed. Use simple comparisons and membership; normalize values at the tool layer (e.g., lowercasing status strings) so conditions stay simple.
Tiny example (before/after):
# Before: overlapping & implicit
- condition: status != "error"
to: cancel_with_fee
- condition: status == "shipped"
to: offer_return
# After: mutually exclusive and explicit
- condition: status == "shipped"
to: offer_return
- condition: status in ["processing","packed"]
to: cancel_with_fee
- condition: status == "error"
to: escalate
5.2 Path vs. Leaf accuracy (what to measure):
When you test a run, you can grade it two ways:
Path accuracy : did the engine take the exact sequence of nodes you expect (e.g., authenticate → check_status → cancel_with_fee → notify_fee → end)?
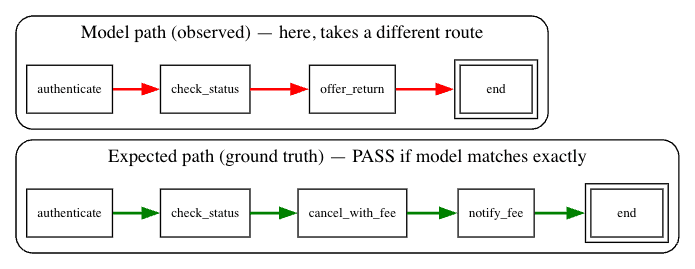
Leaf accuracy: did it end up at the correct final node/action, regardless of intermediate steps?
Useful when intermediate steps are flexible/workarounds are OK, as long as the outcome matches policy.
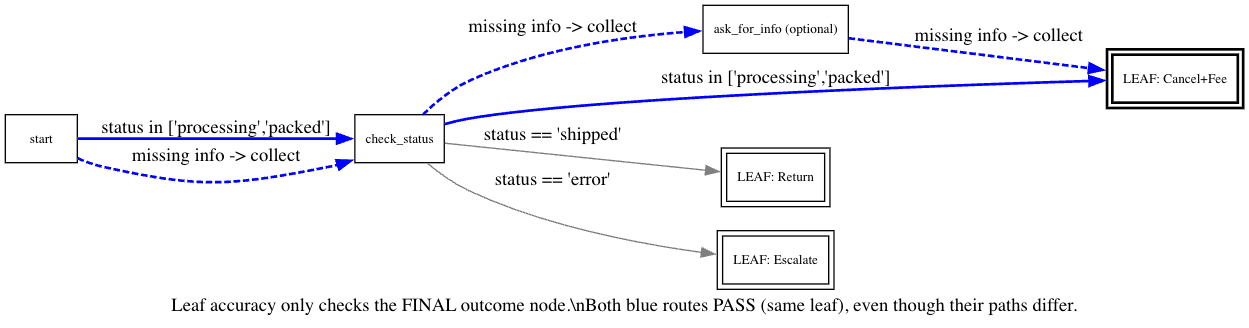
You’ll want both: path for policy compliance and UX, leaf for business correctness.
5.3 Monte-Carlo style checks (quick and strong)
Generate scenarios: sample `status` from `{ "shipped", "processing", "packed", "error" }`, vary flags like `is_vip`, `within_return_window`, etc.
Run the engine for each case and assert the expected path and/or final node.
Log surprises: any “no valid edge” or “multiple edges true” event is a bug or a hole in your SOP.
For the e-commerce example:
A1-like draws (`status="shipped"`) must go **offer_return → end**.
A2/A3-like draws (`"processing"|"packed"`) must go **cancel_with_fee → notify_fee → end**.
A4-like draws (`"error"`) must go **escalate → end**.
If something else happens, either a tool is returning unexpected data or your conditions overlap/miss a case.
5.4 Logs that actually help (observability) Log one record per step with:
node (name), description
allowed_tools (what the agent was permitted to call)
action run at this node (name + args)
observation(normalized dict merged into the blackboard)
matched_edge(condition string) and >next_node
elapsed_ms (per tool and per step)
This gives you:
Audit trails for compliance.
Heatmaps of which edges fire most/least (find dead code).
Diff when a SOP change alters behavior (did paths or leafs shift?).
5.5 Fuzzing & property tests
“If `status=="shipped"`, the path **never** escalates.”
“If `cancelled==True`, then `fee` is present and ≥ 0.”
“No run exceeds `max_steps`” (loop guard).
These invariants flush out hidden coupling and accidental loops fast.
5.6 Handling the usual failure modes
No valid edge → add/adjust a catch-all; tighten upstream tool normalization.
Multiple edges true → reorder or split conditions so they’re mutually exclusive.
Infinite/long loops → add loop counters; keep a `max_steps` per run.
Tool errors/timeouts → retries with backoff; idempotent side effects; escalate when exhausted.
Ambiguous children → use the dummy explore pattern (LLM chooses a subtree first) so decisions stay crisp.
5.7 Versioning & change management
Tag each SOP with a version and a graph hash (from the YAML).
Log runs with `(sop_version, graph_hash)` so you can replay past behavior.
Use PR reviews for SOP diffs;they’re readable (YAML) and business-friendly.
Keep fallbacks if a new SOP underperforms, roll back quickly.
5.8 Benchmarks that matter to you In addition to path/leaf accuracy:
Decision latency (p50/p95) and cost (if using an LLM).
Steps per run (depth) and LLM calls per run (keep low with good SOPs).
Tool failure rate and **escalation rate** (are we over-escalating?).
Branch entropy: are some decisions basically random? That’s a prompt/SOP smell.
5.9 How this ties to our two implementations
Deterministic engine: perfect for building the testing harness—everything is repeatable.
LLM-decider variant: run the same tests but record the chooser prompts and outputs; your harness should verify that the chosen tool is in the allow-list and that the SOP still routes correctly. For ambiguous forks, verify the model first chooses a dummy and later a real action inside that subtree.
Conclusion & what to build next
SOP-Agent turns a messy, policy-heavy workflow into something a model can’t easily derail: humans write the SOP, we compile it into a decision graph, and an execution loop acts, observes, and routes with guardrails. You can run it deterministically for perfect reproducibility or let an LLM decide at the few steps where judgment actually helps—always inside the SOP’s rails.
Policy first, AI second. The SOP defines order, legality, and exits; the model only chooses among allowed actions and proposes arguments.
Deterministic when you need it. The no-LLM engine is cheap, fast, and fully auditable.
Agentic when it matters. The LLM-decider adds judgment and handles unstructured inputs while the SOP still governs routing.
Readable + testable. Simple condition DSL, path/leaf accuracy, and per-step logs make behavior easy to reason about.
Where to go from here
Plug in your real tools. Replace the demo functions with your APIs/DB calls and normalize outputs so conditions stay simple.
Tighten guardrails. Add per-tool schemas, numeric bounds, and postconditions (e.g., “must set `status` before proceeding”).
Measure & iterate. Track path/leaf accuracy, LLM calls per run, latency/cost, and escalation rates; fix overlapping or missing edges.
Handle ambiguity the paper’s way. Use dummy `explore_subtree_*` tools whenever sibling nodes share the same action or lack one, so the agent commits to a branch before deeper decisions.
Productionize. Add retries, idempotency, rate limits, `max_steps`, versioned SOPs, and structured logs for audits.
Optional: LangGraph/StateGraph. If you already use them, map nodes→states and edges→transitions; keep the same allow-list + JSON chooser contract.
Let’s build together
We combine experience and innovation to take your project to the next level.